时间序列相似性查询与索引方法研究
邱均平 王菲菲
(武汉大学中国科学评价研究中心 430072)
摘 要 时间序列相似性查询从提出到现在已有10多年的历史,取得了大量的研究成果。索引既是时间序列相似性查询实现的关键,也是信息技术领域的热点问题之一。近年来,国内外学者为进一步提高查询的完备度而对时间序列索引方法进行了深入的研究。本文在阐述时间序列查询原理的基础上,对各种索引方法进行了阐述和比较,以期对时间序列分析的研究和应用有所启发和帮助。
关键词 时间序列 相似性查询 索引
1 时间序列数据分析概述
时间序列是指同一种现象在不同时间上的相继观察值排列而成的一组数字序列,它广泛存在于经济活动和科学应用中。时间序列可以被描述成一系列按时间点取得的观测值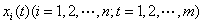 ,当
,当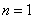 时,称为单变量时间序列,当
时,称为单变量时间序列,当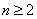 时则表示为多变量时间序列,通常用
时则表示为多变量时间序列,通常用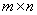 矩阵来表示,其中
矩阵来表示,其中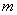 是观察值的个数,
是观察值的个数,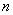 是样本的个数【1】。
是样本的个数【1】。
传统的时间序列分析是概率统计学的一个重要研究领域,着重研究具有随机性的动态数据,研究方法着重于全局模型的构造。模型法是目前对时间序列进行深层次分析的主要方法,主要包括移动平均法、指数平滑法、Box-Jenkins ARIMA/ARMA模型、ARCH模型、神经网络模型、贝叶斯模型以及一些模糊集方法等。模型法中的理论模型是在数学理论和假设基础上,通过演绎推理的方法建立起来的。各种模型都有坚实的数学基础,只要假设合理,所得出的结论就是合理的。但如果所提出的假设不合理,模型法将会严重失真。另一方面,这些传统的时间序列分析方法主要集中于时间序列数据的建模、滤波和预测等方面,反映的是序列的总体的特征,对序列中隐含的一些局部的细节特征很难表现出来【2】。随着新需求的增加,现代的时间序列分析也渐渐进入了更深层次的研究,主要包括八个方面,即时间序列数据变换、时间序列相似性搜索、时间序列聚类、时间序列分类、时间序列相关规则提取与模式分析、海量时间序列可视化、时间序列预测和时间序列异常检测【3】。接下来本文主要探讨一下其中的时间序列相似性查询以及其中的一个重要环节——时间序列索引。
2 时间序列相似性查询的原理
时间序列的相似性查询是在时间序列数据集中发现相似的变化模式,是一种新型、重要的分析方法,对于时间序列的预测、分类以及进行知识发现等具有重要意义。时间序列相似性查询最早是由IBM公司的Agrawal等人1993年提出的,该问题被描述为“给定某个时间序列,要求从一个大型时间序列数据库中找出与之最相似的序列”【4】。
时间序列相似性查询分为全序列匹配和子序列匹配两种方式:1)查询序列和被查询序列的长度相同,称为全序列匹配;2)在较长的时间序列中,找出与查询序列相似的子序列,称为子序列匹配。全序列匹配中涉及的问题主要有:数据的预处理,相似性度量,时间序列的表示和索引结构的组织与实现等;子序列匹配中,除了有全序列匹配中涉及的问的问题外,时间序列的超高维特性使得匹配结果的候选集非常大,即序列中任何一个时间点开始的任何长度的子序列都有可能是查询结果,从而使得子序列匹配中消耗过多的时间【5】,这也就是多维时序数列的降维问题以及查询的准确率与效率的权衡问题。
相似性度量是衡量两个序列相似性的依据,是相似性查询的基础。一方面,相似性度量影响到查询的完备性;另一方面,相似性度量的选择决定了相似性查询能否支持时间序列的各种变形;同时,相似性度量的选择还影响到时间序列的索引方法。时间序列相似性度量主要分为两步完成:1)从时间序列中收集用以度量的特征,然后表示为一定的形式;2)设计公式去度量表示之间的距离。现有的表示方法主要完成第一步工作,而第二步主要通过距离度量方法完成。目前典型的时间序列数据表示主要有离散傅里叶变换(DFT)、奇异值分解(SVD)、离散小波变换(DWT)、分段线性表示(PLR,包括PLA、PAA、APCA)、符号表示法(SA)以及界标模型(Landmarks)等【2,3】。
欧几里德距离(Euclidean Distanc,ED)和动态时间弯曲(DynamicTimeWarping,DTW)是用于时间序列相似性度量的两种经典方法,其中欧氏距离是使用最早也是最广的一种相似性度量。在计算两条时间序列之间的欧式距离时,要求两条时间序列的长度相等。将长度为n的时间序列看作是n维欧式空间中的一个点,它的坐标值分别是时间序列在各个时刻的取值,那么两条长度为n的时间序列之间的欧几里德距离就是n维空间中两个点之间的距离。其数学形式描述如下:给定两条时间序列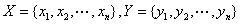 ,它们之间的欧几里德距离定义为:
,它们之间的欧几里德距离定义为: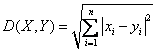 。它的推广形式也称为Miknowksi距离,也称为
。它的推广形式也称为Miknowksi距离,也称为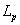 距离,公式为:
距离,公式为: ;当
;当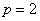 时,Miknowski距离就是欧几里德距离;当
时,Miknowski距离就是欧几里德距离;当 时,称为曼哈顿距离;当
时,称为曼哈顿距离;当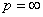 时,称之为最大距离。
时,称之为最大距离。
欧式类距离的优点是计算简单、容易理解,并且满足距离三角不等式,但不支持时间序列的线性漂移和时间轴伸缩;为了支持时间序列的时间轴伸缩,使得时间序列的相似波形能够在时间轴上对齐匹配,Berndt等将在语音识别中广泛使用的动态时间弯曲距离引入到时间序列的相似性查询中,可以用来进行序列长度不相等情况的比较【6】。动态时间弯曲用于计算两个时间序列之间的最大相似性,也即是求最小距离。这种计算方法是时间序列相似性度量所特有的,其计算公式如下: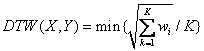 ,其中
,其中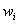 是两个序列对应点
是两个序列对应点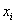 、
、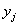 的距离
的距离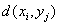 ,
,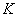 为较长序列的长度。通常采用迭代的方法计算。其过程主要有两步:1)从两个序列的起始点开始迭代计算两个序列
为较长序列的长度。通常采用迭代的方法计算。其过程主要有两步:1)从两个序列的起始点开始迭代计算两个序列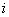 、
、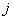 两点的
两点的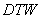 距离
距离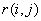 ,
,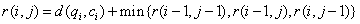 ,其中
,其中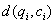 是两个点之间的直接距离,可以由用户选择不同的距离度量,比如Miknowski距离。2)取两个序列结束点的距离为两个序列的距离【7】。动态时间弯曲可以获得很高的识别、匹配精度,但是计算的时间复杂度比较大,而且不满足三角不等式,在低维特征空间中无法保证检索的完整性,也不能方便地在查询时过滤不相似的序列。针对这些不足,有很多学者对该方法进行了改进研究,例如Keohg等人提出了分段时间弯曲距离,在时间序列分段线性表示的基础上,提取每个分段的均值,将均值序列的动态时间弯曲距离定义为分段时间弯曲距离;他们还提出衍生动态时间弯曲距离,估计时间序列上各点的导数,用该导数序列代替原时间序列进行动态时间弯曲距离的计算,减少了计算DTW距离的时间复杂度。还有一种思路是采用可快速计算的LowerBounding距离首先过滤部分不满足相似性要求的时间序列,然后再针对剩下的候选集采用动态时间弯曲距离进行筛选,以减少DTW距离的计算量【8】。另外,还有学者将主成分分析【6】、小波变换【9】、向量空间法【7】等引入时间序列的相似性度量中,进一步提高了相似性查询的完备性。
是两个点之间的直接距离,可以由用户选择不同的距离度量,比如Miknowski距离。2)取两个序列结束点的距离为两个序列的距离【7】。动态时间弯曲可以获得很高的识别、匹配精度,但是计算的时间复杂度比较大,而且不满足三角不等式,在低维特征空间中无法保证检索的完整性,也不能方便地在查询时过滤不相似的序列。针对这些不足,有很多学者对该方法进行了改进研究,例如Keohg等人提出了分段时间弯曲距离,在时间序列分段线性表示的基础上,提取每个分段的均值,将均值序列的动态时间弯曲距离定义为分段时间弯曲距离;他们还提出衍生动态时间弯曲距离,估计时间序列上各点的导数,用该导数序列代替原时间序列进行动态时间弯曲距离的计算,减少了计算DTW距离的时间复杂度。还有一种思路是采用可快速计算的LowerBounding距离首先过滤部分不满足相似性要求的时间序列,然后再针对剩下的候选集采用动态时间弯曲距离进行筛选,以减少DTW距离的计算量【8】。另外,还有学者将主成分分析【6】、小波变换【9】、向量空间法【7】等引入时间序列的相似性度量中,进一步提高了相似性查询的完备性。
3 时间序列索引方法比较
时间序列数据库包含的数据量是非常庞大的。为了提高查找的效率,需要对被查找的时间序列建立索引。索引技术的关键问题是如何划分数据空间,以及如何根据划分方法将数据组织起来,索引的组织很大程度上是依赖于相似性度量的。目前大部分相似性度量是基于Euclidean空间距离的,因此其索引方式也大部分采用空间索引结构。空间索引是指依据空间对象的位置和形状或空间对象之间的某种空间关系,按一定顺序排列的一种数据结构,其中包含空间对象的概要信息【10】。从大的方面分,空间数据索引技术可分为树结构(包括R树、K-D树、四叉树)和网格文件两类【5】。时间序列索引的一种方式就是直接采用这些空间索引技术,首先对这些传统的索引方法进行比较【11】:
1)R树类包括R树及其变形,如R+树、R*树、SR树等。这些数据结构都是平衡树,用于处理多维数据,访问二维或更高维对象组成的空间数据。R树类索引方法的基本思想是:根据数据分布,将向量空间划分为若干个最小外接矩形MBR,再将父MBR根据空间包含关系划分为若干子MBR,如此反复,自上而下构成一个树形结构。其中,叶节点直接指向数据对象,树节点MBR之间允许重叠。
2)KD-树是k维的二叉查找树,二叉查找树在多维空间的扩展,主要用于索引多属性的数据或多维点数据。K-D树是一个非平衡树,不同数据插入顺序会产生不同结构的K-D树。在K-D树中,数据不仅出现在叶结点上,也可以分散在树的任何地方。K-D树虽然对存储要求比较低,但却增加了树的深度,不利于海量数据存储,树的更新也比较困难。
3)四叉树实际上是指在k维数据空间中,每一节点有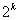 子树。用于对空间点的表示与索引。每个节点存储了一空间点的信息及个子节点的指针。在四叉树创建时,首先将整个空间划成四个相等的子空间,然后对每个或其中几个子空间再继续划分,这样就形成了一个基于四叉树的空间划分。同R树相比,四叉树可以用顺序存储的线性表来表示索引,内存需求量小,插入和删除操作更加简单、方便,有利于查询速度的提高。但四叉树是一种非平衡树,在建立索引之前必须预先知道空间对象所分布的范围,可调节性比较差。
子树。用于对空间点的表示与索引。每个节点存储了一空间点的信息及个子节点的指针。在四叉树创建时,首先将整个空间划成四个相等的子空间,然后对每个或其中几个子空间再继续划分,这样就形成了一个基于四叉树的空间划分。同R树相比,四叉树可以用顺序存储的线性表来表示索引,内存需求量小,插入和删除操作更加简单、方便,有利于查询速度的提高。但四叉树是一种非平衡树,在建立索引之前必须预先知道空间对象所分布的范围,可调节性比较差。
4)网格文件(Grid File)是一种典型的基于哈希表的数据存取方式,它的基本思想是根据一正交的网格划分k维的数据空间。k维数据空间的网格由k个一维数组表示,这些数组称为刻度。将其保存在主存。刻度的每一边界构成k-1维的超平面。整个数据空间被所有的边界划分成许多k维的矩形子空间,这些矩形子空间称为网格目录,用k维的数组表示,将其保存在硬盘上。网格目录的每一网格单元包含一外存页的地址,这一外存页存储了该网格单元内的数据目标,称为数据页。一数据页允许存储多个相邻网格单元的目标。网格文件索引方法的优点是算法实现较为简单,结合编码技术可以快速实现目标查询;缺点是数据冗余较大、缺少层次、灵活性差、无法实现多分辨率。
空间数据相似性查询一般是通过提取空间数据的特征来进行相似性匹配,这些特征一般都表达为高维特征向量,于是解决相似性查询问题的关键就是高维空间数据索引【12】。对于时间序列的索引,通过提取其主要特征,将时间序列映射到高维空间中的点,然后可以直接利用高维数据索引方法。另外,还有很多学者针对时间序列的具体特点和要求,对高维空间数据索引技术加以改进或直接设计出专门的时间序列索引方法。
Agrawal等研究了全序列查询问题,利用离散傅立叶变换将时间序列变换到频域空间,然后提取前k个离散傅立叶系数作为一个多维特征向量来表示时间序列,再利用R*树作为其索引组织结构实施快速查询【4】。这一索引技术被命名为F-索引。Faloutsos等将Agrawal等提出的技术,扩展到子序列匹配问题上,创立了ST索引方法:首先其定义一个最小查询序列长度w,该长度是已知的;然后采用滑窗方法,用长度为w的滑动窗口放在序列的每一个起始位置,就可以获得一段长度为w的子序列,对这段序列进行离散傅立叶变换即得到一些列系数;取前k个参数作为该子序列的特征值,将该序列变成k维特征空间上的点,沿时间轴逐点移动滑动窗口即可得到多个子序列,抽取全部子序列的特征即可形成了一个多维空间;把多维空间中的点映射到一个最小边界矩阵作为查找过滤的条件,最后采用R*树等方法实现子序列的查询【13】。该索引方法下查询的高精确度是以高数据冗余为代价的。Kim等利用图论理论对ST索引进行了改进,使子序列查询效率有了比较大的提高【14】。Bozkaya等针对不用长度相似性度量提出了一种称为vp-tree(vantage point tree)的索引结构。该方法的主要思想是:利用一种可以编辑的距离,认为两个序列之间其相同元素达到一定程度,则认为它们是相似的,因此在序列组织时按照它们的长度进行聚类组织索引。在查询实现上,vp树主要是利用度量空间的三角不等式性质进行空间数据的过滤,减少参与相似性匹配计算的特征向量个数,进而快速检索。这种方法应用比较简单,但是由于它们的相似性不是基于一个距离度量空间的,可能导致查询的不完备,造成查找正确结果的遗漏【15】。Faloutsos等对动态时间弯曲距离的情况进行了索引探讨,提出了一种叫FastMap的索引结构,通过多次在超平面上的投影来组织时间序列,使相似性查询只需在部分数据上进行,节省了查询的时间。然而FastMap索引需要预先知道不同对象之间的距离,同时它也是一种粗的过滤方式,会带来许多不相似结果的引入【16】。针对符号化的时间序列,有的学者还提出了一种字符串索引方法——互关联后继树来进行查询效率的改进和时序频繁模式挖掘的研究:最初,为了减少索引项,只有那些首字母和次字母不同的后缀才被储存,利用后继树建立索引;后来人们对互关联后继树进行了改进,提出了一种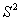 树,用于子序列查询,可以实现找出两个序列最长的相同模式【2】。国内学者蒋嵘和李德毅等还提出了基于云模型时间序列形态概念树,在时间序列分段线性化表示的基础上,实现对时间序列形态的自然描述,将连续的斜率或角度转换为有限的自然语言概念表示,实现基于形态表示的时间序列相似性查询【17】。翁小清和沈钧毅针对由区间数组成的时间序列,还提出了一种基于低分率聚类的索引方法:首先从区间数序列中识别重要区间数形成新的序列,然后利用K-均值聚类方法对这些重要区间数序列分成k个类,用这些类作为区间数序列数据库的索引;当查询时,算法从待查询的区间数序列中抽取前n个重要区间数并组成重要区间数序列,计算该重要区间数序列到k个类中心的距离,选取与之距离最短的类;最后,计算这个类中每一个区间数序列与前n个重要区间数序列的距离,与之距离最短的那个区间数序列,即为查询结果。该方法通过识别区间数时间序列中的重要区间数,使得区间数时间序列的维数大幅度降低,而且加快了区间数时间序列的查找过程,不会出现漏报现象【18】。
树,用于子序列查询,可以实现找出两个序列最长的相同模式【2】。国内学者蒋嵘和李德毅等还提出了基于云模型时间序列形态概念树,在时间序列分段线性化表示的基础上,实现对时间序列形态的自然描述,将连续的斜率或角度转换为有限的自然语言概念表示,实现基于形态表示的时间序列相似性查询【17】。翁小清和沈钧毅针对由区间数组成的时间序列,还提出了一种基于低分率聚类的索引方法:首先从区间数序列中识别重要区间数形成新的序列,然后利用K-均值聚类方法对这些重要区间数序列分成k个类,用这些类作为区间数序列数据库的索引;当查询时,算法从待查询的区间数序列中抽取前n个重要区间数并组成重要区间数序列,计算该重要区间数序列到k个类中心的距离,选取与之距离最短的类;最后,计算这个类中每一个区间数序列与前n个重要区间数序列的距离,与之距离最短的那个区间数序列,即为查询结果。该方法通过识别区间数时间序列中的重要区间数,使得区间数时间序列的维数大幅度降低,而且加快了区间数时间序列的查找过程,不会出现漏报现象【18】。
4 结束语
自上个世纪90年代以来,时间序列数据分析得到越来越多研究者的关注和重视。时间序列相似性查询是时序数据分析的重要问题,至今还没有得到很好地解决。相似性度量是时间序列相似性查询的基础,时间序列的索引技术则可以提高相似性查询的效率,是查询实现的关键环节。本文沿着时间序列相似性查询与索引技术的研究路线阐述了相似性查询的基本原理,并对当今的一些改进思路做了探析;同时还对各种时序索引方法进行了介绍和比较,这对于索引的建设工作和研究具有一定的参考价值。
参考文献
1 YANG K, SHAHABIC. A PCA-based similarity measure formultivariate time series[C], Proceedings of MMDB’ 04. New York, NY, USA, ACM, 2004: 65-74.
2 曲吉林. 时间序列挖掘中索引与查询技术的研究[D]. 天津大学,2006:6-10.
3 贾澎涛,何华灿,刘丽,孙涛. 时间序列数据挖掘综述[J]. 计算机应用研究,2007, 24(11):15-18.
4 Agrawal R,Faloutsos C,Swami A,Efficient Similarity Search in Sequence Databases,Proc.4th Int.l Conf Foundations of Data Organizationand Algorithms,Chicago,IL,Oct,1993:69~84.
5 左新强. 时间序列的相似性查找方法研究[D]. 清华大学,2007:2-7.
6 周大镯,吴晓丽,闫红灿. 一种高效的多变量时间序列相似查询算法[J]. 计算机应用,2008,28(10):2541-2543.
7 刘懿,鲍德沛,杨泽红,赵雁南,贾培发,王家钦. 新型时间序列相似性度量方法研究[J]. 计算机应用研究,2007,24(5):112-114.
8 肖辉. 时间序列的相似性查询与异常检测[D]. 复旦大学, 2005:33-40.
9 曲文龙,张德政,杨炳儒. 基于小波和动态时间弯曲的时间序列相似匹配[J]. 北京科技大学学报,2006,28(4):396-402.
10 郭菁,周洞汝,郭薇,胡志勇. 空间数据库索引技术的研究[J]. 计算机应用研究,2003,(12):12-14.
11 曲吉林,寇纪淞,李敏强. 图像检索中索引技术研究[J]. 情报科学,2006,24(4):579-583.
12 夏宇,朱欣焰. 高维空间数据索引技术研究[J]. 测绘科学,2009,34(1):60-62.
13 Faloutsos Christos,Ranganathan M,Manolopoulos Yannis,Fast subsequence matching in time-series databases,In:proc.ACMSIGMOD,Minneapolis MN, May 25~27,1994:419~429.
14 Kim,E.,Lam,J.M.&Han,J,AIM:approximate intelligent matching for time series data,In proceedings of Data Warehousing and Knowledge Discovery, 2nd Int'l Conference.London,UK,Sep 4-6,2000:347-357.、
15 Bozkaya,T.and Ozsoyoglu,M.Indexing large metric spaces for similarity search queries.ACM Trans.Database Syst.24,3,Sep.1999:361–404.
16 Faloutsos C,Ranganathan M,Manolopoulos Y,Fastmap:A fast algorithm for indexing,data-mining and visualization of traditional and multimedia datasets, In Proc.ACM DIGMOD International Conference on Management of Data, May 1995:163-174.
17 蒋嵘,李德毅,基于形态表示的时间序列相似性搜索[J].计算机研究与发展,2000,37(5):601-608.
18 翁小清,沈钧毅. 基于聚类的区间数时间序列的索引方法[J]. 计算机工程,2006,32(22):4-6.
邱均平 教授,博导,武汉大学中国科学评价研究中心主任,中国索引学会副理事长。
王菲菲 福建省泉州市图书馆工作。