2003-2013年我国大数据领域研究论文计量分析
赵蓉英1,2,3 王 嵩1
(1) 武汉大学信息管理学院 武汉 430072)
(2) 武汉大学信息资源研究中心 武汉 430072)
(3)武汉大学中国科学评价研究中心 武汉 430072)
摘 要 以CNKI为数据源,通过对国内近10年大数据研究论文进行文献计量、高频关键词可视化分析等方式,揭示了本领域微观、中观、宏观3个热点研究现状和面向企业与面向技术的2个主要研究趋势。
关键词 大数据 文献计量 共词分析 知识图谱
在信息时代,大数据被称作是“未来的新石油”,其概念通常被认为是一种数据量很大、数据形式多样化的非结构化数据。[1]大数据不但蕴含有巨大的科研价值,还隐含有巨大的经济价值。正因于此,对大数据的研究逐渐引起国内外学者的广泛关注。本文拟通过从发文增长规律、作者分布、高产作者机构分布及高频关键词等方面,使用统计分析和可视化的方法,对2003年至2013年以来国内大数据研究论文的文献增长、核心机构及研究重点展开分析,在全面了解国内有关大数据研究现状的基础上,总结其研究热点和发展趋势。
1 数据来源和研究方法
1.1 数据来源
本文以CNKI中国期刊全文数据库、博硕论文数据库和会议论文数据库为数据来源,选定检索条件为:主题=大数据+big data,时间限定为2003-2013年的数据,并设定“精确”匹配以提高检准率,统计时间为2013年6月22日,共检索到期刊文献3514篇,博硕论文1999篇,会议论文146篇,合计共5659篇文献。
1.2 研究方法
利用EXCEL和SPSS软件作为数据分析处理工具,结合文献计量学方法,统计分析近十年大数据研究论文的发展规律和研究热点。
2 文献增长规律分析
2011年,麦肯锡研究院在《大数据:创新、竞争和生产率的下一个前沿》的报告中提出了“大数据”时代已经到来;2012年3月,美国奥巴马政府宣布投入2亿美元启动“大数据研究和发展计划”,这是继1993年美国宣布“信息高速公路”计划后的又一次重大科技发展部署[1、2]。而通过对发文数量的统计显示,2011年之前的发文数量呈现缓慢增长态势,2011年之后文献量急速增长,这也正与上述提到的时间点相吻合,具体统计如表1所示。
表1 2003-2013年大数据研究论文数量统计
年代(年) | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 |
论文(篇) | 169 | 221 | 359 | 369 | 452 | 454 | 487 | 558 | 640 | 1201 | 734 |
通过绘制普赖斯曲线[3]后发现(如图1所示),大数据研究文献的增长量规律由经典指数定律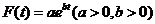 ,(其中
,(其中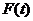 为时刻t的文献量,a为条件常数,b为时间常数,即持续增长率),可得
为时刻t的文献量,a为条件常数,b为时间常数,即持续增长率),可得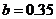 ,文献翻倍的时间
,文献翻倍的时间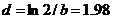 。
。
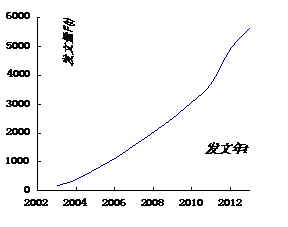
图1 2003-2013年大数据研究论文普赖斯曲线
3 作者分布规律分析
3.1 作者数据分布情况
本文统计的5659篇论文中第一作者共计4854人,人均发表论文数0.86篇,全部作者共计5884人,可见合著率不高。设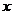 为作者撰写的论文数量,
为作者撰写的论文数量,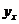 为撰写
为撰写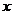 篇论文的作者数量,分别对其取对数得:
篇论文的作者数量,分别对其取对数得: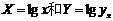 见表2所示。并根据所得数据绘制图2所示的洛特卡分布曲线[3],同时为表现和
见表2所示。并根据所得数据绘制图2所示的洛特卡分布曲线[3],同时为表现和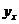 之间良好的线性关系,在计算图2中斜率
之间良好的线性关系,在计算图2中斜率 时,将大于6篇的高产作者数量不予考虑。
时,将大于6篇的高产作者数量不予考虑。
表2 2003-2013年大数据研究论文作者数据统计
论文数 (篇/人) | 作者数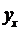 | 论文总数 | 
| 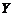
| 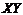
| 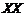
|
1 | 4643 | 4643 | 0 | 3.6667 | 0 | 0 |
2 | 170 | 340 | 0.301 | 2.2304 | 0.6714 | 0.0906 |
3 | 23 | 69 | 0.4771 | 1.3617 | 0.6497 | 0.2276 |
4 | 7 | 28 | 0.6021 | 0.8451 | 0.5088 | 0.3625 |
5 | 5 | 25 | 0.699 | 0.699 | 0.4886 | 0.4886 |
6 | 2 | 12 | 0.7781 | 0.301 | 0.2342 | 0.6054 |
7 | 1 | 7 | 0.8451 | 0 | 0 | 0.7142 |
8 | 1 | 8 | 0.9031 | 0 | 0 | 0.8156 |
∑ | | | 4.6055 | 9.1039 | 2.5527 | 3.3046 |
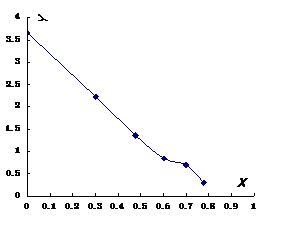
图2 2003-2013年大数据研究论文洛特卡分布曲线
对论文作者机构数据进行统计后发现(见表3),发文量在10篇以上的作者单位几乎全部为重点高等院校,体现出其对大数据研究的重视与投入。
表3 2003-2012年大数据研究论文作者机构数据统计
序号 | 作者机构 | 出现频次 | 百分比% |
1 | 中国科学院研究生院 | 43 | 0.8238 |
2 | 东北大学信息科学与工程学院 | 22 | 0.4215 |
3 | 华中科技大学计算机科学与技术学院 | 21 | 0.4023 |
4 | 中国科学院计算技术研究所 | 19 | 0.3640 |
5 | 中国科学技术大学电子科学与技术系 | 18 | 0.3448 |
6 | 四川大学计算机学院 | 15 | 0.2874 |
7 | 吉林大学计算机科学与技术学院 | 15 | 0.2874 |
8 | 北京航空航天大学电子信息工程学院 | 15 | 0.2874 |
9 | 清华大学计算机科学与技术系 | 14 | 0.2682 |
10 | 国防科技大学计算机学院 | 14 | 0.2682 |
11 | 国防科学技术大学计算机学院 | 13 | 0.2490 |
12 | 华南师范大学计算机学院 | 13 | 0.2490 |
13 | 国防科技大学电子科学与工程学院 | 13 | 0.2490 |
14 | 中国科学院长春光学精密机械与物理研究所 | 13 | 0.2490 |
15 | 北京交通大学计算机与信息技术学院 | 13 | 0.2490 |
16 | 合肥工业大学计算机与信息学院 | 13 | 0.2490 |
17 | 信息工程大学测绘学院 | 11 | 0.2107 |
18 | 中南大学信息科学与工程学院 | 11 | 0.2107 |
19 | 西安电子科技大学雷达信号处理国家重点实验室 | 11 | 0.2107 |
20 | 北京航空航天大学计算机学院 | 11 | 0.2107 |
21 | 武汉大学测绘遥感信息工程国家重点实验室 | 11 | 0.2107 |
22 | 中国电信股份有限公司广东研究院 | 11 | 0.2107 |
23 | 江苏大学计算机科学与通信工程学院 | 10 | 0.1916 |
24 | 上海大学计算机工程与科学学院 | 10 | 0.1916 |
25 | 中国科学院近代物理研究所 | 10 | 0.1916 |
26 | 中国农业大学信息与电气工程学院 | 10 | 0.1916 |
27 | 华中科技大学电子与信息工程系 | 10 | 0.1916 |
28 | 西安交通大学电子与信息工程学院 | 10 | 0.1916 |
3.2 洛特卡分布定律
美国统计学家洛特卡于1926年提出反映作者生产能力的洛特卡定律原始表述是:在某一时间内,写了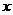 篇论文的作者数占作者总数的比例
篇论文的作者数占作者总数的比例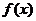 与其所撰写的论文数
与其所撰写的论文数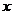 的平方成反比,即
的平方成反比,即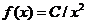 。故,洛特卡定律又称平方反比定律,上述公式为其经典表达式,该定律第一次揭示了论文作者与论文数量之间的关系,广义的洛特卡定律用公式可表示为:
。故,洛特卡定律又称平方反比定律,上述公式为其经典表达式,该定律第一次揭示了论文作者与论文数量之间的关系,广义的洛特卡定律用公式可表示为:
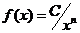 (1)
(1)
其中,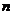 与
与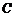 是对应这些特定数量集合的两个常数。即
是对应这些特定数量集合的两个常数。即 是反映论文量和作者人数关系的重要比例参数,是发表一篇论文作者所占百分数。
是反映论文量和作者人数关系的重要比例参数,是发表一篇论文作者所占百分数。
3.2.1 指数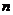 的估算
的估算
令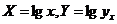 ,得
,得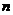 的最小二乘估计公式:
的最小二乘估计公式:
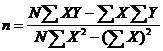 (2)
(2)
其中,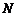 为被考察数据集的数量,在此取全部作者统计总数5884。根据表2,取
为被考察数据集的数量,在此取全部作者统计总数5884。根据表2,取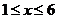 ,剔除
,剔除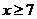 以上的高产作者,共4人,45篇论文,占作者人数的0.0068%,占论文总数的0.0080%。因此,经过公式2计算得
以上的高产作者,共4人,45篇论文,占作者人数的0.0068%,占论文总数的0.0080%。因此,经过公式2计算得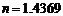 ,符合n的指数在
,符合n的指数在 之间的要求[4]。
之间的要求[4]。
3.2.2指数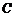 的估算
的估算
洛特卡在对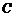 值进行计算时得到
值进行计算时得到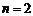 ,但后人验证得知不同学科领域所取数据样本的时间和区间不同时
,但后人验证得知不同学科领域所取数据样本的时间和区间不同时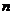 值并不恒为2,
值并不恒为2,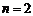 只是个特例[3]。不同学科甚至同一学科的不同发展阶段,
只是个特例[3]。不同学科甚至同一学科的不同发展阶段,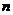 值也不尽相同。美国情报学家帕欧提出的指数不为2时逼近
值也不尽相同。美国情报学家帕欧提出的指数不为2时逼近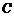 值的计算公式:
值的计算公式:
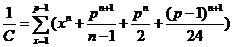 (3)
(3)
上式中,为保证其精确性,当规定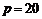 时,误差可以忽略不计[2、4]。因此,当
时,误差可以忽略不计[2、4]。因此,当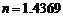 代入(3)式后,得
代入(3)式后,得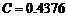 。
。
3.3 核心作者发文量分析[2-3]
由普赖斯理论:发表论文数为 篇以上的作者为杰出科学家即核心作者,其中
篇以上的作者为杰出科学家即核心作者,其中
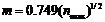 (4)
(4)
上式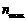 为发文量最多作者的发文篇数,由统计得
为发文量最多作者的发文篇数,由统计得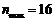 ,则
,则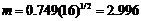 ,即在大数据研究领域核心作者的发文量篇均在4篇以上。
,即在大数据研究领域核心作者的发文量篇均在4篇以上。
4 关键词分析
论文的关键词通常是表达文献的主题内容,对关键词的统计可以反映出其所涉及学科的主题和研究方向。而为更好反映该研究领域的研究热点和趋势,则可以通过对高频关键词的词频进行统计分析。通过对5659篇论文关键词的统计,共得到关键词15684个,频次大于40次的关键词共36个,部分见表4。
表4 2003-2013年大数据研究论文部分高频关键词数据统计
序号 | 关键词 | 出现频次 | 序号 | 关键词 | 出现频次 | 序号 | 关键词 | 出现频次 |
1 | 数据挖掘 | 321 | 10 | 海量数据 | 87 | 19 | 时代 | 62 |
2 | 大数据 | 150 | 11 | 支持向量机 | 82 | 20 | 数据 | 60 |
3 | 数据库 | 119 | 12 | 数据中心 | 82 | 21 | 移动互联网 | 60 |
4 | 数据分析 | 107 | 13 | 数据采集 | 75 | 22 | Hadoop | 58 |
5 | FPGA | 102 | 14 | 企业 | 66 | 23 | 关联规则 | 55 |
6 | 解决方案 | 99 | 15 | 互联网 | 65 | 24 | 大数据量 | 55 |
7 | 聚类 | 97 | 16 | 粗糙集 | 63 | 25 | 聚类分析 | 53 |
8 | 数据仓库 | 95 | 17 | DSP | 63 | 26 | 数据管理 | 52 |
9 | 云计算 | 91 | 18 | 数据处理 | 62 | 27 | MapReduce | 48 |
4.1 高频关键词相似矩阵
对于表4中36个高频关键词两两统计其在同一篇论文中出现的次数,形成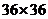 的共词矩阵,用Ochiai系数将其转化为共词相似矩阵,并用SPSS19.0进行聚类分析。部分高频关键词Ochiai系数相似矩阵见表5。
的共词矩阵,用Ochiai系数将其转化为共词相似矩阵,并用SPSS19.0进行聚类分析。部分高频关键词Ochiai系数相似矩阵见表5。
表5 部分高频关键词Ochiai系数相似矩阵
| 数据挖掘 | 大数据 | 数据库 | 数据分析 | FPGA | 解决方案 |
数据挖掘 | 1.000 | 0.064 | 0.015 | 0.108 | 0.000 | 0.011 |
大数据 | 0.064 | 1.000 | 0.015 | 0.047 | 0.000 | 0.000 |
数据库 | 0.015 | 0.015 | 1.000 | 0.089 | 0.000 | 0.028 |
数据分析 | 0.108 | 0.047 | 0.089 | 1.000 | 0.000 | 0.107 |
FPGA | 0.000 | 0.000 | 0.000 | 0.000 | 1.000 | 0.000 |
解决方案 | 0.011 | 0.000 | 0.028 | 0.107 | 0.000 | 1.000 |
表5中的数值表明关键词之间的相似性,如相对应的两关键词距离近、相识度高,其数值将越接近于1,反之则趋近与0。
4.2 高频关键词聚类
高频关键词聚类分析,是以这些关键词两两在同一篇文章中出现的频率(共词)为分析对象,利用聚类的统计学方法,把关联密切的关键词聚集在一起形成类团,以便帮助人们从不同层次和更高抽象角度来理解当前的研究状况。关键词聚类分析时,先以最有影响的关键词(种子关键词)生成聚类;再次,由聚类中的种子关键词及相邻的关键词再组成一个新的聚类。关键词越相似它们的距离越近,反之,则较远[5]。利用SPSS19.0对上述相关系数矩阵进行系统逐次聚类分析,得到的聚类结果见图3。图中上端0-25的标度代表各类之间的距离,越早被聚类为一类的关键词之间的距离最近、关联越紧密。
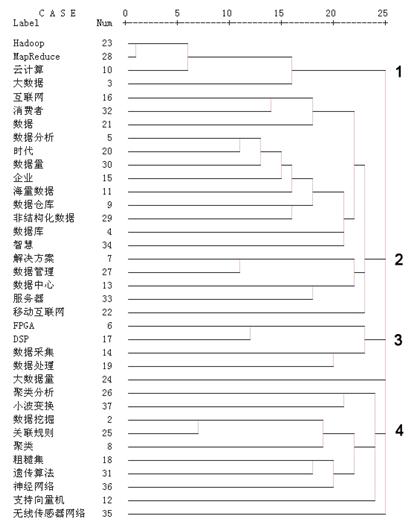
图3 2003-2013年大数据研究论文高频关键词聚类图
笔者依据图3的聚类结果将高频关键词归结为四大类。大类1是以“云计算”、“Hadoop”为代表的能够对大数据进行分布式管理、处理的软件框架,和以“并行数据库”、“MapReduce”为主流实现平台的大数据分析[6],主要是对提出可靠、高效、可伸缩的大数据处理方式等领域的研究;大类2是研究在互联网环境下企业对大数据管理与分析的需求,提出各种数据中心等解决方案来满足企业对数据资源的需求;大类3是对大数据采集与处理的数字化方式的研究,利用FPGA、DSP等数字化器件实现高速、高效处理;大类4包含了对大数据特性描述,以及数据挖掘和聚类分析两个方面,前者包括非结构化、数据存储与融合等特性,后者主要对大数据管理的关键技术研究。
4.3 高频关键词多维尺度分析
多维尺度分析是用于反映多个研究对象间相似(不相似)程度,将这种相似(不相似)程度在低维度空间(通常是二维或三维)中用点与点之间的距离表示出来,通过空间距离的远近来显示其相似性的高低[7],以宏观全面地表现高频关键词之间的联系,揭示知识单元的分布结构[8]。图4为大数据研究论文高频关键词多维尺图,图中相似度高的关键词点聚集在一起形成一类,成为学科研究的热点,且越居中的关键词与其他关键词的联系越多,在该领域中的地位越核心[9,10]。
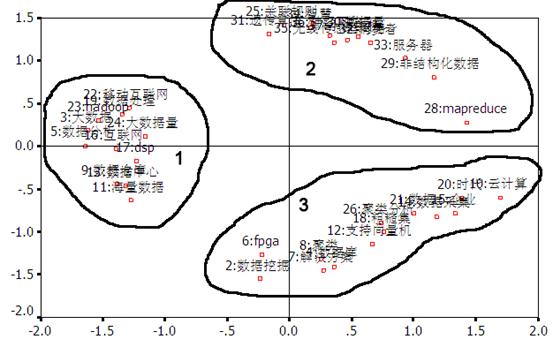
图4 2003-2013年大数据研究论文高频关键词多维尺度分析
从图4的大数据高频关键词多维尺图分析,可以聚集出三大类团。类团1中互联网、数据中心等较为靠近图谱中心,表明近10年大数据研究围绕以互联网为平台的海量数据存储或获取等方面开展研究;类团2中各个高频词距图谱中心位置趋于相近,研究领域是源于大数据的非结构化特性展开,在关联规则、算法研究等关键技术方面进行研究;类团3中,聚类离中心位置相对较近,本类团以云计算、数据采集等为起源,过渡为对大数据聚类分析的热点研究。
从以上通过对关键词的聚类分析和多维尺度分析的结果可以发现,近十年国内有关大数据研究的论文大致可以归结为三个部分:一是概述大数据中观层面研究的实际意义,描述企业、个人如何从大数据中获益,突出大数据的重要性;二是对大数据关键技术的研究,包括存储技术、聚类分析、数据挖掘、数据检索等算法和技术的研究[11],从宏观层面展开对大数据相关内容的研究;三是在微观层面的研究,针对具体行业或领域的大数据类型,通过研发相应的数字化、高速化的处理方式来展开。
5 结语
本文以计量分析和可视化的方式对近10年国内大数据研究论文进行了统计分析,可以得知,国内对大数据的研究主要还是在最近几年才逐步成为热点,并取得了一系列的理论和实践成果,产生了巨大的经济效益。
从研究热点角度,形成了两个主要领域:以科学技术作为推动力,诸如大数据的高效采集与处理、存储与表示、数据挖掘与聚类,以及低能耗的数据处理、存储与通信新技术等[2,12];另一个主要领域是以巨大经济效益为推动力的大数据研究,推动如甲骨文、微软、IBM等跨国软件巨头不断推出大数据处理技术,云计算、Hadoop等便是其中的典型代表。
从作者角度,合著和高产作者均不多,且单位相对集中在高校和科研院所,而从大数据中获利最大的企业却对此投入却并不多。在另一方面,对大数据时代的信息安全研究较为匮乏,在爆出“棱镜门”事件后,各国信息安全问题凸显,解决当前的大数据核心技术挑战,全面强化未来的信息网络安全战略安全[13],必须将大数据研究上升到国家信息安全战略层面。
参考文献
1 刘明,李娜.大数据趋势与专业图书馆[J].中华医学图书馆情报杂志,2013(2):1-6
2 李国杰.大数据研究的科学价值[J].中国计算机学会通讯,2012(9):8-15
3 邱均平.信息计量学[M].武汉:武汉大学出版社,2007
4 杜朝东,王沁,孙亮等.论文作者与论文数量的洛特卡分布研究――以1994-2010年的《大学图书馆学报》为例[J].贵图学刊,2011(01):53-56
5 邱均平,王明芝.1999~2008年国内数字图书馆研究论文的计量分析[J].情报杂志,2010(2):1-5
6 王珊,王会举,覃雄派等.架构大数据:挑战、现状与展望[J].计算机学报,2011(10):1741-1752
7 郭文斌,方俊明,陈秋珠.基于关键词共词分析的我国自闭症热点研究[J].西北师大学报(社科版),2010(1):128-132
8 马费成,李小宇.我国信息政策法规研究现状、热点与进展分析[M].情报学研究进展,2010
9 邓中华,孙建军.网络环境下共词分析方法的应用研究[J].图书馆杂志,2008(12):17-21
10 Small H. Co-Citation in Scientific Literature :A newMeasure of the Relationship Between Publications[J].Journal of the AmericaSociety of Information Science ,1973(24):265-269
11 王秀磊,刘鹏.大数据关键技术[J].中兴通讯技术,2013(6)
12 孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013(1):146-169
13 陈明奇,姜禾,张娟等.大数据时代的美国信息网络安全新战略分析[J].信息网络安全,2012(8):32-35
14 崔雷.书目共现分析系统《用户使用说明书》[Z/OL]. [2013-06-25].http://wenku.baidu.com/view/2304b16a7e21af45b307a843.html
15 CFA论坛.CFA论坛SPSS专区[Z/OL].[2013-07-02].http://bbs.cfaspace.com/forum-88-1.html
赵蓉英 女,教授,博士生导师,研究方向:信息计量与科学评价。
王 嵩 男,武汉大学信息管理学院博士研究生,研究方向:信息计量与科学评价。