基于多策略的领域本体术语抽取研究*
何 琳
(南京农业大学信息管理系 210095)
摘 要 术语的抽取是领域本体构建的基础工作,决定了本体构建的质量。获取的术语除了要求有准确的短语识别率,还要求有较高的术语领域度。本文试图研究一种不依赖于背景语料的术语领域度筛选方法。本文的主要工作集中在两个方面:一是通过统计和规则相结合的方法从领域语料中抽取候选术语(短语),二是提出了通过候选术语的分布度、活跃度以及主题度进行计算的多策略术语抽取方法,并通过实验进行了验证和分析。实验结果表明,在小规模航空航天领域语料库上进行验证性实验后发现,在不大量增加计算时间复杂度的情况下,能够有效提高领域术语抽取的质量,获得令人较满意的结果。
关键词 术语抽取 多策略 术语分布度 术语活跃度 术语主题度
Abstract: Terminology extraction is one of the most important basic prepare work for ontology construction, which assured the qualification of ontologies for building. The acknowledged terminology should not only have high recognized precision, but also have high termhood in the domain. This paper tried to find a method for terminology extraction not relied on background corpus supported. Our work focused on two aspects, one is discussing a phrase recognized approach based on statistical and Chinese grammar rule, and the other is that we proposed an approach for termhood calculation of candidate terminology which synthesized three factors of distribution degree, activity degree and subject degree. Experiment on testing corpus shows that our method can have good result in terms of precision and recal1.
Keywords: Terminology Extraction, Integrated Strategy, Distribution Degree, Activity Degree, Subject Degree
1 引言
领域术语是在特定领域内具有语义的词或短语的集合。从某种意义上讲,领域术语是领域知识在文本中的外在表现。领域术语的获取就是从领域文本集合中抽取最能够代表该领域的概念集合,这个过程包括从领域文本中抽取候选术语集合、词性规范(同义词处理)以及领域术语的筛选和确定。术语的抽取是领域本体构建的基础工作,决定了本体构建的质量。获取的术语除了要求有准确的短语识别率,还要求有较高的术语领域度,也就是该领域的核心概念,而非通用意义上的短语。以往的术语抽取研究更多的是关注术语的外在形式(短语)获取的准确率,对于术语的领域度研究,主要集中于利用领域语料和背景语料进行对比分析。然而背景语料库的构建受到诸多因素的影响。本文试图研究一种不依赖于背景语料的术语领域度筛选方法。本文的主要工作集中在两个方面:一是通过统计和规则相结合的方法从领域语料中抽取候选术语(短语),二是提出了通过候选术语的分布度、活跃度以及主题度进行计算的多策略术语抽取方法,并通过实验进行了验证和分析。
2 相关研究概述
术语抽取包含术语外部形式获取(也即词或词组形式的获取)以及术语领域度的计算(是否为该领域的特有概念)。有的研究将两个步骤分开计算,也有的研究将二者合二为一进行筛选。其中,术语外部形势获取的研究比较多,有基于语言学、统计学以及二者混合的方法。而术语领域度计算的研究目前研究相对比较少,方法比较单一。
2.1 术语外在形式的获取
(1)语言学方法
利用语言学的知识模式识别语料中的术语,包括词性及浅层语法分析,具有较高的准确率[1-2]。但是有限的语言规则并不能概括所有的术语组成规律,而且在不同专业领域、不同语种内,术语的构成规律都有差异,因此,单纯使用语言学方法来抽取术语,会导致总体召回率偏低、系统可移植性差等缺陷,而且规则库的开发和维护都需要耗费大量的人力物力。
(2)统计学方法
统计模型则是建立在大规模语料的基础上,利用术语在整个语料中的分布统计属性来识别出其中潜藏的术语。如TF*IDF方法、KF*IDF方法、C-value/NC-value方法[3-4]等。统计学方法不受语种和领域的限制,但是存在计算量过大,语料规模的限制以及抽取结果需要多次优化过滤等问题。
(3)混合方法
在实际的应用中,大多数研究将二者进行混合使用,先利用语言学方法进行语料识别,然后利用统计学规律进行过滤,或者先利用统计学方法从语料中获取候选术语,然后利用构词规则对统计结果进行优化。
2.2 术语领域度的计算
(1)词频计算
术语领域度计算比较常用的方法是依赖,TF-IDF及其优化策略计算术语的主题表达能力[4][5]。然而这种方法忽略了术语在语料库中的全局信息,对低频术语和基础术语不够敏感,尤其是在大量短语抽取后,低频术语的识别干扰较大。
(2)背景语料对比
领域相关度计算是通过与无关领域比较来反映术语同特定领域的相关度,它假设领域无关的术语在不同领域文档集中的分布是相似的,而领域术语在其特定领域内的使用与其他领域相比却有很大差别。比较典型的方法有,利用术语领域语料和背景语料上的词频比率来抽取术语[6]、通过多领域的比较,引入领域频率的方法[7]、将领域词频与背景词频进行归一化处理[8]等方法。
3 基于多策略的术语抽取方法
3.1 领域本体术语的特点及抽取原则
国家标准GB/T 10112《术语工作原则和方法》[9]中给术语下的定义是:“术语是专业领域中概念的语言指称”,这与ISO国际标准组织的定义是一致的,该定义产生于上世纪90年代,随着本体研究的不断深入,本体中的术语又呈现出了一些新的特点。揭春雨、冯志伟等学者[10]建议把术语的定义扩展为:“术语是专门用途语言中专业知识的语言表达”。这个定义用“专业知识的语言表达”来替代(并涵盖)传统定义中“概念指称”,使得术语遍存在于专门用途语言的不同结构层次上。领域本体中的术语与传统的术语区别主要体现在领域本体具有以下主要特点:
(1)动态性
不仅术语本身的含义和形式是不断发展的,术语的科学定义也不是一成不变的, 而是随着科学研究的发展而变化, 不断起用新的更科学的定义来代替旧的定义。很多科学术语的定义其变化都确切反映人们对于事物的新认识, 反映科学知识的不断深化和发展[11]。
(2)多种词性共存
传统的术语定义把术语限制在狭小的名词和名词词组的范围内,难以包容客观上存在着的为数可观的其他词性的术语,例如:动词、数词、形容词以及副词这些词性的术语在领域本体中发挥着能够描述概念属性的重要作用。
(3)多种变体共存
传统的术语定义非常注重术语的规范化要求,对术语的形态、语法、句法等都有着非常严格的要求。领域本体中的术语的获取趋势是从领域文本中自动抽取和识别,而文本中存在着非常多的术语变体,包括拼写、形态、词形、结构及首字母缩略词等。因此,领域本体构建中的术语更贴近文本的真实特性。
基于以上特点,领域本体的术语抽取需要涵盖各种词性的术语,以满足领域本体构建的需要,同时多种变体的获取也是领域本体术语抽取需要关注之处。因此本文设计了多种抽取和衡量指标,使得领域本体术语的获取能够满足专业性、多态性、全面性以及稳定性,保证获取的术语近可能全面涵盖领域内容,包含多种词性术语以及领域内的新近词汇,同时保证具有一定的稳定性。这些术语是领域本体构建的“采石场”,在此基础上才能进一步进行同义词识别,领域关系识别与获取等工作。
3.2 基于多策略的术语抽取方案总体设计
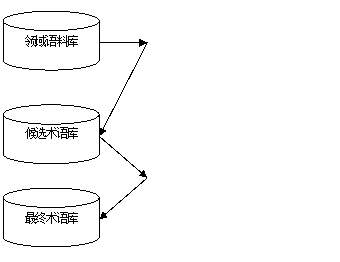
基于多策略的术语抽取方案总体分为两步:一是术语的外在形式的判别,也就是候选术语的获取,主要是借助统计学方法和语言学规则过滤结合的方法从领域文本集中把词和词组抽取出来作为候选术语;二是内在含义的判别,即把抽取的候选术语放在领域内进行考量,计算候选术语的领域度,以判定抽取的词或词组是否是领域内的核心概念。
图1 基于多策略的术语抽取方案总体设计
3.3 候选术语的初步获取方法
本文所采取的领域候选术语获取方法,也即候选术语外在形式的获取借鉴了无辞典分词的方法N-Gram文本表达方法[9],采用部分语法规则辅助筛选N-Gram文本表达造成的噪音从语料库中抽取词或词组作为领域本体构建的候选术语基础[10]。
Step 1停用词的建立,主要是建立正确的分词边界,减少计算量;
Step 2文本预处理,进行文本编码格式的统一以及去除文本中的特殊符号;
Step 3 N-Gram生成,通常词组的长度不超过8个汉字,因此N的取值为16个字节;
Step 4 GF/GL权重值计算,是对抽取的N元字符串进行处理。
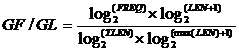 (公式1)
(公式1)
其中,FREQ表示一个字符串在集合中出现的频次,LEN表示一个字符串的长度,TLEN表示文本的长度,max(LEN)表示最大字符串的长度。
Step 5结果初步筛选,定义字符串同其父串(或者子串)之间的长度差异为K。筛选是只对长度相差不超过K的父串或子串进行比较,选择GF/GL值大的保留。
根据汉语的构词特点,词组通常由“名词+名词”、“动词+名词”以及“形容词+名词”等形式构成,其中的数词、量词、介词以及助词构成了噪音。因此,设计了基于规则的筛选方法对提取结果进行过滤:使用“语言技术平台LTP”标注工具对提取结果进行词性标注,去除词头或者词尾中的数词、量词、介词以及助词。经过统计分析,发现经过规则过滤后能有效去除N-Gram文本表达法所带来部分噪音数据。
4 候选术语领域相关度的计算方法
4.1 术语分布度的计算
术语分布度的计算主要是从词频分布的角度对术语的领域度进行衡量,如果一个候选术语在领域文献集合中的词频呈现均衡分布的态势,那么由此可以推断,该候选术语在领域内是一个较为通用的概念,对于描述该领域特点的能力较弱,而非核心术语。如果一个候选术语在领域文献集内的词频分布呈现波动态势,说明该候选术语对于区分领域特点有一定的贡献。一个候选术语如果是某领域的核心术语,取决于两种情况[11]:
①该术语与文档主题关系紧密,在文档中出现的频次很高,且经常出现在文档的关键位置,如题名、文摘中;
②该术语与文档主题不是直接相关,会被提及,但出现频次不高,经常出现在全文中;
如果单纯采用TF-IDF策略进行计算,仅仅能够将该文档中的关键词抽取出来,并不能全面反映该词在整个领域文献集中的分布情况。检验样本和总体分布的波动程度,最直接有效的方法就是利用样本方差。当方差的值越大,表示这个样本的波动越大,也就是具有较好的区分能力。因此,本文采取考虑文本位置加权的候选术语权值计算方法并同时结合候选术语在文档集中的方差进行分布度的计算。
(1)加权的术语权值计算方法
综合考虑语词的频次、出现位置以及词长等因素,提出以下加权方案[12]:
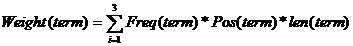 (公式2)
(公式2)
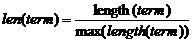 (公式3)
(公式3)
其中,i为整数取值为1、2、3,分别代表词出现在标题、文摘以及全文的情况。Freq(term)为标引词出现在相应位置的绝对词频。len(term)表示候选术语的词长。
(2)样本标准差的计算
为了消除文档集中文档数目以及平均数的不均衡产生的影响,引入变异系数对样本标准差进行计算。
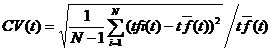 (公式4)
(公式4)
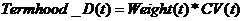 (公式5)
(公式5)
其中,N表示包含候选术语t的文档数;tfi(t)表示候选术语f在第i篇文档中出现的频率;tf(t)表示候选术语f在N篇文档中出现的平均频率。
4.2 术语活跃度的计算
领域术语必须是能够长期稳定地存在于领域内用于特定表达领域特点的词或短语。因此,如果一个候选术语在较长的时间跨度上其稳定程度能够呈线性状态,那么我们则认为它是成为领域术语的必要条件。在本文中,我们设计了候选术语的活跃度来进行候选术语在时间跨度上的表现,为了减小绝对词频差异对结果波动的影响,采用候选术语在某年份内出现频次的排名来进行活跃度的度量。如果一个候选术语在测试年份内的频次排名标准差越小,说明该候选术语的频次排名波动越小,我们认为它的稳定性越高,活跃度越好。
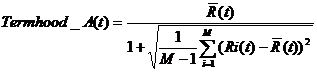 (公式6)
(公式6)
其中,M为候选术语t出现的年份的总数,Ri(t)为t在第i年出现总频次的排名,R(t)为t在M年内排名的平均值。
4.3 术语主题度的计算
术语主题度的计算根据某术语的上下文环境进行计算,如果一个术语是该领域的核心术语,那么与之经常出现的关键词一定是集中于某个主题领域的,反之,如果一个术语不是某领域特征术语,那么与之经常一起出现的关键词在主题方面一定会处于分散状态。基于此,本文中术语的主题度计算,首选抽取与该术语经常出现的关键词,同时计算关键词与该术语的相关度,构建术语上下文环境的向量矩阵,利用层次聚类算法对各关键词进行聚类分析,如果各关键词在主题上能够集中,且候选术语与该主题有较高的领域主题一致度,那么可以认定,该术语是领域内的核心术语。
(1)术语环境主题的聚类方法
Step1 利用相似度计算得到候选术语最相关的K个关键词作为聚类起始点(K=5);
Step2 利用K-means聚类算法,采用average_link方法计算聚类中心,计算与聚类起始点最相关的关键词聚类,重新计算聚类中心;
Step3 重复上述步骤直到聚类中心不再改变为止;
(2)候选术语领域主题集中度的认定
假设领域D中,候选术语t的环境聚类结果为c=(c1,c2,...,cm),那么对于t在领域主题的集中度为:
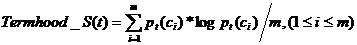 (公式7)
(公式7)
其中,Pt(Ci)指的是候选术语t与聚类结果Ci的依附程度,通过向量相似度进行计算。
4.4 多策略的合成
对于以上各种计算因子进行合并,形成一个统计的、多策略结合的术语领域度计算模型。Composite方法[13]是目前较为通行的对多个算法结果进行合并的有效方法。本文采用该方法对上述三个术语领域度计算方法进行结果合并,计算公式如下:
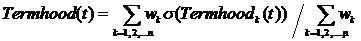 (公式8)
(公式8)
其中,wk是各策略的权重,σ是sigmoid函数,该函数是一个平滑函数,使得合并结果偏向于预测值高的策略,函数σ的定义为:
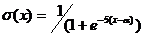 (公式9)
(公式9)
其中,x是某一策略的计算值,α是sigmoid函数中心点,取值为0.5。
5 实验结果与分析
5.1 测试数据
(1)领域语料
我们选取了航空、航天领域1989-2011年所有核心期刊的论文题录数据作为术语抽取的领域语料,共计19种期刊17907篇论文。
(2)测评数据
将《中国航空百科词典》、《世界航天器运载大全》以及《汉语主题词表》中的航空航天范畴的主题词进行汇总,命名为DomainCompare作为术语筛选的评判依据。
5.2 测试方法
(1)候选术语形式正确性的判断
候选术语正确性是指从领域文本中筛选出的候选术语在外在形式上的正确率。仅从外在形式上判断其为词或短语的正确性,不考虑其在领域内的主题表达能力,如,从文本中筛选出了“存储性能”、“故障定位”、“工程技术人员”等词汇。
 (公式10)
(公式10)
(2)候选术语领域度的判断
候选术语领域度的判断是指判断筛选出的词或词组成为该领域核心专业术语的情况。如果筛选出的领域术语属于DomainCompare,则该术语筛选正确。由于我们第一步筛选出的候选术语的长度有些会略大于DomainCompare中的平均词长,因此,判断的时候将筛选出的候选术语和专业术语进行词素切分,如果专业术语的词素全部术语候选术语,则认为该候选术语筛选正确。
 (公式11)
(公式11)
 (公式12)
(公式12)
5.3 实验结果分析
(1)候选术语的形式正确性
利用5.1中构建的语料中进行候选术语的初步筛选,进过N元分词以及包括相邻词比较以及汉语构词规则约束等筛选方法过滤后共得到3016个候选术语(词或短语),经过人工的词形词义判断后,其中属于词或词组的数量为2564个,具体数字见表1。
表1 候选术语形式正确性评价结果
技术措施 | 数值 |
N元分词 | 178,768 |
词频过滤 | 20,148 |
“N元重叠”过滤 | 13,864 |
相邻词比较 | 5,552 |
汉语构词规则过滤 | 3,753 |
剩余数量 | 3,016 |
正确数 | 2564 |
正确率 | 85% |
对测试结果进行分析,K值的选取对于抽取结果有一定的影响。由于父串和字串在进行比较的时候,会生成许多不完整词汇,例如:“北斗在”、“按编队卫星”、“表面形貌上”等。测试中的主要错误集中在对不完整词汇的过滤上。处理的方法是对词汇进行词形分析,利用汉语构词规则对不符合构词规则的词汇过滤或作进一步切分处理,以处理不完整词汇。建立有效的构词规则过滤机制是提高候选术语切分结果的有效方法之一。
表2 候选术语初步筛选结果样例
侧地卫星 | 查分方程 | 嫦娥 | 超高速撞击 |
沉积层 | 超细硼粉 | 超燃冲压发动机 | 长征二号丙 |
科技部 | 启动试验 | 人工神经元网络 | 风云2号 |
倒计时 | 航天推进系统 | 半导体集成电路 | 内弹道学 |
从表2中不难看出,识别出的候选术语只是形式上正确的词或词组,有些词汇,例如“半导体集成电路”、“科技部”以及“倒计时”等可以在多个领域内出现,因此,候选术语领域度的计算将是在此基础上进一步筛选出该领域的核心术语。
(2)候选术语的领域度
根据公式(5)-(7)计算出术语的三种指标,取α=0.5,得出指标评价的综合值(Termhood)。经过多次实验确定如表3所示的过滤阈值,得到最终的术语领域度评价结果如表3所示。
表3 候选术语的领域度筛选评价结果
评价指标 | 过滤阈值 | 正确率 | 召回率 |
Ternhood_Time | 1.36 | 81.6% | 46.8% |
Termhood_Activity | 1.85 | 75.6% | 32.7% |
Termhood_Freq | 2.59 | 86.2% | 38.1% |
Termhood | 3.91 | 90.3% | 31.8% |
从实验结果来看,Termhood_Freq的优势在于通用词过滤的效果很好,因而具有较高的正确率。Termhood_Time具有相对较高的召回率,计算时取值在连续3年区间内称均匀分布的候选术语,该方法在一定程度上过滤了某一术语在某一特定时间点内突增为研究热点,而无法成为领域内稳定的术语对象。Termhood_Activity保证候选术语在领域内具有较高的连通度,使得筛选出的术语彼此之间具有良好的概念关系,减少孤立词的出现,提高本体术语间的关联比,然而由于语料仅采用题录语料,使得候选术语上下文环境聚类时,参与计算聚类成员数量偏少,使得计算结果中孤立点增多,导致术语的主题集中度准确率下降。
表4为采用各计算因子过滤的术语结果样例,从结果来看,过滤结果具有较高的准确性。专业术语词典构建不全面以及参与领域领域度计算的候选术语数量不足(也即候选术语外在形式抽取存在误差)是导致召回率偏低的主要原因。
表4 领域术语筛选结果样例
ID | 术语名 | T_Time | T_Activity | T_Freq | Termhood | Correct |
1 | 制导系统 | 1.896309 | 4.384521 | 3.265986 | 10.41083 | Y |
2 | 点火试验 | 1.97095 | 4.367415 | 3.304971 | 5.354605 | Y |
3 | 月球探测器 | 1.190049 | 3.857012 | 3.307489 | 4.324696 | Y |
4 | 滑翔 | 1.621012 | 3.620687 | 3.339388 | 4.063607 | Y |
5 | 振动控制 | 1.6484753 | 2.709215 | 3.344781 | 4.886512 | Y |
6 | 含硼推进剂 | 1.763412 | 4.43767 | 3.49612 | 11.59388 | Y |
7 | 侦察卫星 | 2.188183 | 1.911628 | 3.502186 | 7.973773 | Y |
8 | 卫星姿态控制 | 2.183695 | 2.997691 | 3.588216 | 7.592897 | Y |
9 | 性能参数 | 1.986628 | 3.04138 | 2.22185 | 6.39056 | N |
10 | 精度分析 | 2.041708 | 2.048306 | 2.284885 | 18.82592 | N |
从以上结果不难看出,采用三种计算指标的综合值可提高领域术语领域度过滤的准确性。在没有较好的背景语料的对比下,采用本文提出的术语领域度过滤方法可以较好地将领域内的核心术语筛选出来,同时筛选出的术语彼此间具有较丰富的概念关系,便于下一步本体概念关系的构建。
6 结语
领域术语抽取是领域本体构建的基础性工作。有关术语领域度的计算方法主要采用背景语料对比计算的方法,然而许多领域,尤其是中文不具备较好的可供使用的背景语料。本文尝试提出了一种不依赖背景语料的术语外在形式获取的方法以及候选术语领域度的计算方法,将这些处理策略结合起来,在小规模航空航天领域语料库上进行验证性实验后发现,在不大量增加计算时间复杂度的情况下,能够有效提高领域术语抽取的质量,获得令人较满意的结果。术语的抽取仅仅是本体构建的最基础性工作,下一步的工作将在识别的领域术语的基础上,利用多种语料环境进行术语的各种关系的抽取和识别。
*本文系教育部人文社会科学青年基金项目《基于知识组织资源仓库的中文本体自动构建研究》(项目编号09YJC870015)以及中央高校基本科研业务费专项基金(KYZ201159)《面向qRT-PCR实验的内参基因挖掘技术研究》的研究成果之一。
参考文献
1 Didier Bourigault, Electlicit De France. Surface Grammatical Analysis for the Extraction of Terminological Noun Phrases [C]//Proceedings of COLING'92. Association for Computational Linguistics. France, 1992: 977-981
2 Justeson J S, Katz S M. Technical terminology: Some linguistic properties and an algorithm for identification in text[J]. Natural Language Engineering,1995,1(1): 9-27
3 Frantzi K T,Ananiadou S,Mima H.Automatic Recognition of Multi-word terms:the C-value/NC-value Method[J].International Journal on Digital Libraries, 2000, 3(2): 115-l30
4 Nakagawa.Experimental Evaluation of Ranking and Selection Methods in Term Extraction [M ].Recent Advances in Computational Terminology.2001: 303-326
5 Manning C D,Sehtze H. Foundations of Statistical Natural Language Processing[M].Cambridge Massachusetts:MIT Press.1999
6 K. A. Ahmad, H. Fulford, M. Rogers.W hat is a term? The semi-automatic extraction of terms from text[J]. Translation Studies. An Inter-discipline (1994):267-278
7 Uchimoto K, Sekine S,Murata M,et a1. Term recognition using corpora from different fields [J].Terminology,2001, 6(2): 233-256
8 Chung T.A corpus comparison approach for terminology extraction [J].Terminology,2003,9(2): 221-246
9 GB/T 10112-1999 术语工作原则与方法[S]
10 揭春雨, 冯志伟. 基于知识本体的术语定义(下)[J].术语标准化与信息技术, 2009(3): 14-23
11 冯志伟. 术语学中的概念系统与知识本体[J]. 术语标准化与信息技术, 2006(1) : 9-14
9 张雪英. 基于粗糙集理论的文本自动分类研究[D] . 南京: 南京理工大学, 2005.6
10 何琳. 领域本体的半自动构建及检索研究[M]. 南京: 东南大学出版社, 2009
11 周浪等. 基于多策略融合的中文术语抽取方法.情报学报, 2010,29(3): 460-467
12 侯汉清, 章成志, 郑红. Web概念挖掘中标引源加权方案初探[J]. 情报学报, 2005,24(1): 87-92
13 Do H. Rahm, E. Coma: A system for flexible combination of schema matching approaches[C]. // Proceedings of the 28th International Conference on Very Large Data Bases,Hong Kong,2002: 610-621
何 琳 女,1980年生,南京农业大学信息管理系副教授,主要研究方向为信息检索、本体构建,发表论文20余篇,出版专著1部。