受控语言在国内网络数据库中的应用与展望
李 琳 华薇娜
(南京大学信息管理系 210093)
摘 要 本文从国内网络数据库现状和检索实例出发,发现目前我国网络数据中受控语言应用存在的问题,并结合国内外研究成果,展望受控语言在我国网络数据库中的应用前景。
关键词 受控语言 分类语言 主题语言 网络数据库
随着信息时代的进一步发展,对网络数据库中庞大的信息资源进行有效组织以实现用户在网络数据库平台上的资源共享,已成为网络数据库信息组织研究的主要方面。网络数据库中的信息量大、范围广、更新频繁,若采用规范化较低或没有规范化的语言进行标引与检索,检索质量往往不稳定,容易导致漏检、误检。同时,由于这类语言未进行同义词、相关词处理,用户检索时很难依靠自己的了解查全同一概念的不同词形及进行相关词的检索,也会增加用户负担,影响查全率。从自然语言出发,并依据一定的规则进行事先规范的受控语言(包括分类语言和主题语言在内)为这一问题的解决提供了可能。本文从国内网络数据库现状和检索实例出发,发现目前我国网络数据中受控语言应用存在的问题,并结合国内外研究成果,展望受控语言在我国网络数据库中的应用前景。
1 受控语言在国内网络数据库中的应用现状及问题
1.1 受控语言在国内网络数据库中的应用现状
1.1.1 万方数据知识服务平台
万方数据知识服务平台是建立在百余个数据库基础之上的大型中文网络信息资源系统。该系统以科技信息和商情信息为主,涵盖文化、教育等相关信息的综合性信息服务系统。在万方数据知识服务平台首页的检索界面上(图1),除一个快速检索框外,还提供了跨库检索的途径,包括标题、中图分类号、关键词、摘要等检索字段。其中,中图分类号检索体现出万方数据知识服务平台利用分类语言――《中国图书馆分类法》组织信息,但通观所有的检索界面,均未提供中图分类号的联机展示链接或是检索分类号信息的途径。因此,利用中图分类号进行检索,要求用户在检索前必须对《中国图书馆分类法》有所了解,或是利用其他检索途径找到部分相关文献后,利用这些文献的分类号再进行检索。这不仅没有为检索用户提供更加快捷的检索途径,反而对用户的检索知识提出更高的要求,不利于非专业用户的使用。
从受控主题语言来看,万方数据知识服务平台未采用主题语言进行信息组织,而其利用的关键词是自然语言中的一种。这种方法虽然查找方便,但是返回的信息过多,导致查准率、查全率均不高。同时,用户也不可能将所有相关的词汇全部想到,从而影响用户全面获得所需的信息。从万方数据知识服务平台提供的知识脉络服务中,也可以发现该数据库不使用主题语言带来的影响。图2是“受控语言”的知识脉络图,但在搜索框中输入“受控词”后,该系统又提供了可进行检索的另外两个相关词,分别为“受控词表”和“受控词汇”。可见,基于未经规范化处理的词汇而统计出的万方数据知识脉络图存在一定的疏漏,不能完全地反映出某知识或研究领域的发展情况,影响了其参考价值和作用。
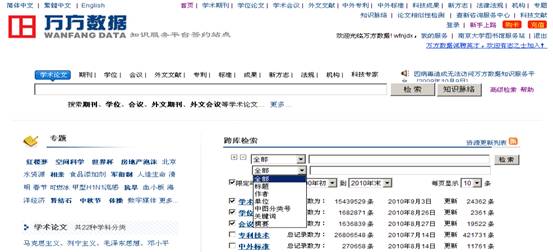
图1 万方数据知识服务平台首页
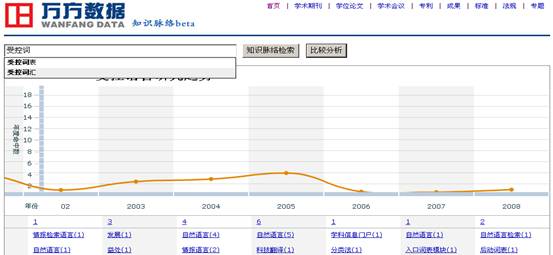
图2 万方数据知识服务平台中“受控语言”的知识脉络
1.1.2 CNKI中国学术文献网络出版总库
CNKI中国学术文献网络出版总库是中国知识基础设施工程的建设成果之一,内容涵盖了我国自然科学、工程技术、人文与社会科学期刊,以及博硕士论文、报纸、图书、会议论文等公共知识信息资源。在检索首页(图3)的内容特征中,提供了全文、题名、主题、关键词、中图分类号检索字段。其中,该数据库的中图分类号字段与万方数据知识服务平台的中图分类号字段一样,提供了从分类角度检索文献的方式,但CNKI也未提供中图分类号的联机展示链接或是检索分类号信息的途径,使得用户在利用该字段检索时应具备一定的基础知识。
与万方数据知识服务平台相比,CNKI中国学术文献网络出版总库的检索字段少了摘要字段,而多了主题字段。从字面来看,CNKI中国学术文献网络出版总库应该是使用主题语言对信息进行组织,但从其检索范围和规则来看,仍是利用自然语言进行信息组织。这是因为主题字段是在题名、关键词、摘要三个字段进行检索,且检索规则依然是按照精确匹配或模糊匹配,并未使用规范化的检索语言组织信息。由此可见,CNKI中国学术文献网络出版总库中的主题字段不是真正意义上的主题检索,而是自然语言检索。
与万方数据知识脉络图相似,CNKI学术趋势以可视化的方式展现学术研究热点、发展趋势,但与万方存在的问题一样,CNKI也是基于自然语言――关键词来统计学术趋势。由于不同人员表达方式的差异,会对学术趋势的统计结果产生一定影响。
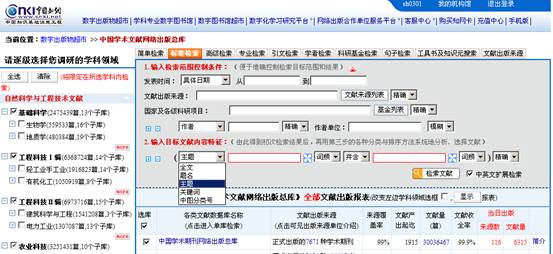
图3 CNKI中国学术文献网络出版总库首页
与万方数据库只依靠用户搜集相关检索词不同,CNKI提供了相关词检索,可以帮助用户查找与检索词相关的词汇,但检索结果(图4)中的21个相关词并不完全是同义词或近义词,且所覆盖同义词或近义词有限。可见,该功能对查全率要求不高的用户来说有一定帮助,而对于查全率要求较高的用户来说,仍需进一步补充检索词。
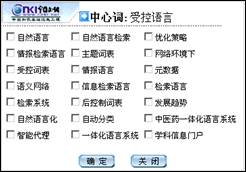
(a) (b)
图4 CNKI提供的相关词界面
1.1.3 维普中文科技期刊数据库
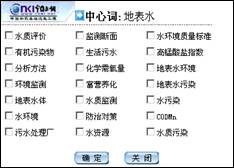
维普中文科技期刊数据库作为我国三大知名数据库之一,涵盖了自然科学、工程技术、农业科学、医药卫生等八大领域的中文期刊文献。在该系统的首页(图5)上可以看到,维普数据库提供的12个检索字段,其中的分类号字段与上述两系统的中图分类号字段对应。但与前两个数据库系统不同的是,维普中文科技期刊数据库还提供了分类检索界面,同时在该界面上还提供了《中国图书馆分类法》的联机展示,如图6所示。在分类检索界面,可以将类别一层层点开,寻找与检索需求相关的类别。以查找“地表水体污染防治与处理”相关文献为例,在万方数据知识服务平台上只能根据用户自身积累的知识和试检结果来调整、完善检索式;在CNKI中国学术文献网络出版总库中,还可以利用词扩展,来寻找相关词汇,以调整、完善检索式;而在维普中文科技期刊数据库中,则可以直接利用分类检索完成用户的检索需求,如图6所示。由此可见,中图分类号的联机展示的确可以帮助用户快速定位到所需的文献信息,但是如果用户不了解中图分类体系,则要花费较多的时间在寻找具体类别上。此时,若能提供检索中图分类号的渠道,将会提高检索的效率。从受控主题语言来看,维普中文科技期刊数据库也未采用主题语言进行信息组织,仍是利用自然语言――关键词组织信息。
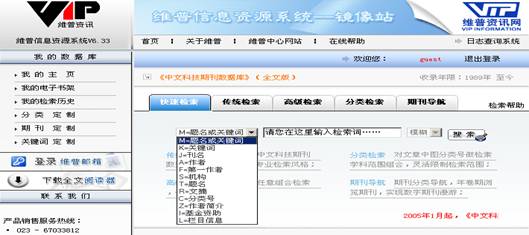
图5 维普中文科技期刊数据库首页
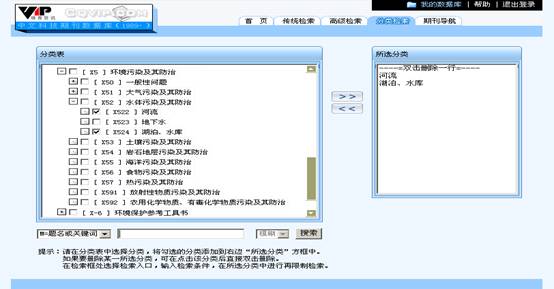
图6 维普中文科技期刊数据库分类检索界面
1.2 国内网络数据库应用受控语言存在的问题
通过对我国三大主要网络数据库中受控语言的应用现状的描述,不难发现我国网络数据库在受控语言应用方面存在以下问题:
(1)分类语言在我国网络数据库信息组织中应用较为普遍,主要运用《中国图书馆分类法》来组织信息。但是在三大主要网络数据库中,仅维普中文科技期刊数据库提供了联机展示途径,且这三个数据库均未提供检索中图分类号信息的途径,不利于非专业用户的使用。
(2)主题语言在我国网络数据库信息组织中很少使用。目前,我国三大主要网络数据库均未使用主题语言组织信息。虽然在CNKI中国学术文献网络出版总库中提供了主题字段进行检索,但这仍是基于关键词的自然语言检索途径。
(3)《中国图书馆分类法》是我国网络数据库普遍采用的分类体系,用于区分文章的学科类别,但是文章与图书毕竟不同,将图书分类法不加调整或修订地直接用于文章分类,其通用性需进一步考量。
2 受控语言在网络数据库中的应用与研究进展
2.1 受控语言在国外网络数据库中的应用与研究进展
在使用国外网络数据库的过程中,不难发现每个数据库均不同程度地使用受控语言组织信息,且分类表和主题词表的种类也十分多样。
(1)DERWENT专利数据库:该数据库中除了使用国际专利分类法(InternationalPatent Classification,IPC)对收录的专利数据进行标引外,该数据库还有自己专利分类法――德温特分类代码(Derwent Class Code)。
(2)Ei Village2系统实现了在一个界面上可同时对多个数据库进行跨库检索的功能,检索结果中剔除了重复数据。在这些数据库中存在众多的分类表与词表,分类表包括:EI分类法(Ei Classification(CAL)code)、国际专利分类法(IPC)、美国专利分类法(US Classification)、欧洲专利分类法(ECLA code)、Inspec分类法、COSATI(美国联邦科学技术情报委员会分类法)、NTIS SubjectCategory Classification(美国国家技术情报局主题类目分类法)、ICS(国际标准分类法)、FSC(美国联邦标准)分类法。主题语言词表包括:《工程标题词表》(SubjectHeadings for Engineering,简称SHE)、《工程叙词表》(EngineeringInformation Thesaurus,EIT)、INSPEC叙词表。
(3)剑桥科学文摘数据库(CSA)中也涉及到了众多的分类表和词表,分类表包括:金属文摘(METADEX)分类、铝工业文摘(Aluminum IndustryAbstracts)分类、陶瓷/世界陶瓷文摘(Ceramic Abstracts/WorldCeramic Abstracts)分类、铜资料中心数据库(Copper Data Center Database)分类、工程材料文摘(Engineered Materials Abstracts)分类、材料商业档案(Materials Business Files)分类、焊接检索(WELDASEARCH)分类。主题语言词表包括:冶金叙词表(Thesaurus of Metallurgical Terms)、工程材料辞典(Engineered Materials Thesaurus)、生命科学叙词表(Life Sciences Thesaurus)、美国国家航空航天局词典(NASA Thesaurus)、美国教育研究资源中心叙词分类法(ERIC DescriptorsThesaurus)、水产科学与渔业叙词表(ASFAThesaurus,AquaticSciences & Fisheries)、政治科学索引语词叙词表(Thesaurus of Political Science Indexing Terms)、科技术语表(Technology Terms)、铜词表(Copper Thesaurus)、心理学词表(PsycINFO Thesaurus)、社会学索引语词叙词表(Sociological Indexing Terms)。
(4)MEDLINE数据库(国际性综合生物医学信息书目数据库)中使用的MeSH(Medical Subject Headings,医学主题词表)。
从上述部分数据库应用受控语言的实例来看,在分类语言使用方面,各数据库根据其收录文献范围的不同,分别设立了相应的分类方法或是采用相应的国际通用分类方法;在主题语言方面,各数据库采用的主题词表不同,且部分大型网络数据库中同时存在多种主题词表。目前,对主题词表质量的影响因子、作者关键词对主题词表的影响、词表最优训练集、利用主题词表构建跨语言检索系统,以及在受控语言基础上构建本体、语义导航等研究是国外在受控词表方面最新的研究成果[1-6]。
2.2 受控语言在国内网络数据库中的应用与研究进展
通过对我国主要网络数据库受控语言应用现状的介绍发现,《中国图书馆分类法》是期刊、报纸、会议文献数据库主要采用的分类方式。在专利信息组织方面,我国的专利信息数据库也均采用《国际专利分类表》对专利信息进行分类;在标准信息方面,我国的标准信息采用《中国标准分类》、《国际标准分类》两种分类方法进行组织;在科技成果数据库中则采用《中国图书馆分类法》和《学科分类与代码》两种分类方法组织信息。由此可见,分类语言在我国网络数据库中应用较为普遍。并且,目前国内对分类语言的研究多集中在对已有分类表的修订、改造及相关技术等研究,也有少量新分类表出现[7-9]。
在主题语言方面,《汉语主题词表》是我国编制的第一部大型综合性中文叙词表,但在我国大型网络数据库中并未采用。此外,《中国中医药学主题词表》、《农业科学叙词表》、《国防科学技术词表》等专业领域主题词表虽然也在不断地完善,但在我国网络数据库中并没有大范围地使用起来。而目前对主题词表的研究,除了对国外现有词表的介绍外,词表的自动构建、词间关系处理,以及本体的构建等研究是我国研究人员较为关注的方面[11-13]。
3 受控语言在国内网络数据库中的应用展望
(1)相对于受控语言在国外大型网络数据库中的广泛应用,我国大型网络数据只是在分类语言应用方面的表现较为显著,但是从易用性角度还说,不便于非专业用户使用。若是能够在目前的相关词查询服务中提供相关分类号信息,如拓展CNKI中国学术文献网络出版总库的相关词查询服务,帮助用户寻找检索词的同时,使用户不再局限于关键词检索,提供给用户从其他检索途径获得所需信息的方法。
(2)图书分类法在我国网络数据库中广泛使用,但在国外网络数据库中未看到将图书分类(如《杜威十进分类法》)应用于期刊文章分类。虽然《中国图书馆分类法》在部分学科分类方面有待改进,但是由于国内使用频率较高的大型网络数据库多是综合型数据库,收录信息的范围十分广泛,《中国图书馆分类法》基本上能够满足这些数据库的使用需要。而小型专业数据库由于其用户不多,并且编制新分类法又耗时耗力,因此在《中国图书馆分类法》基础上建立学科分类法已成为一种普遍采用的、经济高效的方法。
(3)目前,我国已编制的主题词表不在少数,且对主题词表的研究也较多,但还没有一种主题词表被广泛的使用。虽然现在的关键词检索有利于用户及时获取最新的研究信息,但是在获取研究领域的整体发展信息方面存在一定问题。若我国网络数据库能够提供词表的联机检索、展示,或是入口词与主题词转换功能,帮助用户利用主题词检索所需信息,则不仅能够提高用户检索的查全率与查准率,更能简化用户的检索步骤,提高检索效率。
参考文献
1 Pinto M. A user view of the factors affectingquality of thesauri in social science databases [J]. Library & Information Science Research, 2008,30(3):216-221
2 Gil-Leiva I,Alonso-Arroyo A. Keywords given by authors of scientific articles in databasedescriptors [J]. Journalof the American Society for Information Science and Technology, 2007,58(8):1175-1187
3 Sohn S, Kim W,Comeau DC, Wilbur WJ.Optimaltraining sets for Bayesian prediction of MeSH (R)assignment [J]. Journalof the American Medical Informatics Association, 2008, 15(4):546-553
4 Lu WH, Lin RS, Chan YC, Chen KH. Using Webresources to construct multilingual medical thesaurus for cross-languagemedical information retrieval [J]. DecisionSupport Systems, 2008, 45(3):585-595
5 Pei MH, Nakayama K, Hara T, Nishio S. Constructing a Global Ontology by Concept MappingUsing Wikipedia Thesaurus[C]// 22ndInternational Workshops on Advanced Information Networking and Applications,New York, 2008:1205-1210
6 Papadakis I, Stefanidakis M, TzaliA. Semantic Navigation on the web: the LCSH case study [J]. Metadata and Semantics, 2009: 279-288
7 陈立华.对《中图法》(四版)F类目结构的分析与调整[J].大学图书情报学刊,2010,28(2): 63-65
8 薛春香,侯汉清.面向数字环境的《中图法》通用复分表修订思考[J].中国图书馆学报,2009,135(184):61-65
9 何琳,刘竟,侯汉清.基于《中图法》的多层自动分类影响因素分析[J].中国图书馆学报,2009,135(184):49-55
10 吴雯娜,曾建勋.叙词表微观结构的描述与评价――EI叙词表与中文叙词表的对比分析[J].图书情报工作,2009,53(8):12-16, 20
11 曾文,王惠临.主题词表自动构建技术研究[J].情报理论与实践,2010,33(6):117-120
12 倪皓,侯汉清.叙词间等级关系处理和显示的比较分析――兼论叙词词间关系处理和显示的新进展[J].国家图书馆学刊,2009,(3):78-81
13 金晶,宋敏霞,徐晨琛,李楠.基于主题词表的政务领域本体构建[J].图书情报工作,2010,54(8):16-20
李 琳 女,1984年生,南京大学信息管理系情报学专业2009在读博士研究生。
华薇娜 女,南京大学信息管理系教授。