基于集成学习的自动标引方法研究①
章成志1, 2
(1 中国科学技术信息研究所 北京100038)
(2 南京理工大学信息管理系 南京210094)
摘 要 目前大多数自动标引方法不能有效利用文本中包含的多个特征。而支持向量机、条件随机场模型等统计机器学习模型能够有效利用文本包含的多种特征进行关键词提取。同时,由于各种自动标引模型性能各异,综合利用各种模型进行集成学习方式的自动标引,能够提高自动标引的质量。为了进一步提高自动标引的质量,本文试图整合统计机器学习模型与集成学习方法的优势,对文档进行基于多分类模型综合投票方式的自动标引。实验结果表明,基于集成学习方法的自动标引能提高标引结果的查准率和召回率。另外,集成学习标引模型中,基分类器加权的标引结果,优于基分类器未加权的标引结果。
关键词 自动标引 关键词提取 集成学习
1 引言
关键词自动提取是一种识别有意义且具有代表性片段或词汇的自动化技术[1]。在图书情报界,关键词自动提取通常被称为自动标引。在计算语言学领域通常着眼于术语自动识别[2-3]。由于关键词是表达文件主题意义的最小单位,因此大部分对非结构化文件的自动处理,如自动摘要、自动分类、自动聚类等,都必须先进行关键词提取的动作,再进行其他处理。从这一点来说,关键词提取是所有文件自动处理的基础与核心技术[4]。
目前大多文档,包括Web页面通常都不具有关键词,同时手工标引费时费力且主观性较强, 因此关键词自动提取是一项值得研究的技术[4],自动标引方法可分为四类:(1)统计方法。该方法不需要复杂的训练过程,简单易行,主要途径有N-Gram[5]、词频[6]、TF*IDF[7]、字同现[8]、词共现[9]、PAT-tree[10]及特征组合[11]等。(2)语言学方法。主要从词法分析[12]、句法分析[13]、语义分析[14-15]及篇章分析[16-17]角度进行关键词提取。(3)机器学习方法。通过对训练数据进行训练获得统计参数,进行样本的关键词提取,如NB[18]、最大熵模型[4]、SVM[14]、CRF[19]、Bagging[13],相关系统如GenEx[20]、KEA[21]。(4)其他方法,即上述方法的综合运用或集成一些启发式知识,如词位置[22],词长、词排版规则、Html标记[23-24]等。
目前的自动标引方法,大多数不能有效利用文本中包含的多个特征。而支持向量机、条件随机场模型等统计机器学习模型能够有效利用文本包含的多种特征进行关键词提取。同时,由于这些模型标引性能各异,综合利用各种模型进行关键词抽取,能够提高关键词抽取的准确率。早在1993年,储荷婷就曾撰文指出:“从已有的自动标引实践可以看出,博采各法长处的综合自动标引法将称为今后自动标引研究的方向之一”[25]。十年后,即2003年,AnetteHulth利用Bagging算法进行了基于集成学习的自动标引的初步研究[13]。到目前为止集成学习的方法依然是自动标引方法发展的方向之一[26]。
为进一步提高自动标引质量,本文试图整合统计机器学习模型与集成学习方法的优势,对文档进行基于多分类模型综合投票方式的自动标引,并进行标引质量评估。其中基分类器包括条件随机场模型、支持向量机模型、多元线性回归模型、Logistic回归模型以及两个基准模型等。另外,本文还对基分类器加权与不加权两种情况下的自动标引质量进行了评估。
2 基于集成学习的关键词提取方法
本节首先对集成学习进行概述,对一般的集成学习算法进行了描述。然后给出几个用于自动标引的基分类器,利用这些基分类器进行基于集成学习的自动标引。
2.1 集成学习概述
集成学习(EnsembleLearning)通过利用多个学习器来解决同一个问题,可以获得比单个学习器更强的泛化能力,因此,它受到了机器学习界的广泛重视,并被国际机器学习界权威学者Dietterich称为当今机器学习的四大研究方向之首[27]。集成学习方法又称组合方法。在分类中,它根据训练数据构建一组基分类器(Base Classifier),然后通过对每个分类器的预测进行投票来进行分类[28]。Schapire和Singer[29]将Boosting 用于文本分类,他们通过实验发现,在文本分类任务上,Boosting 的效果始终优于或相当于Rocchio等常用技术。Weiss 等[30]利用集成学习技术成功地在使用小词典的基础上达到了很高的分类精度。
2.2 一般集成学习算法描述
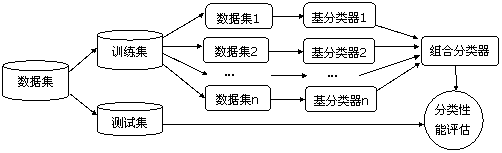
图1 集成学习方法逻辑视图
图1给出了集成学习方法逻辑视图②。构建组合分类器的方法有如下几种[28]:
通过处理训练数据集,如Bagging方法[28]和Boosting方法[28];
通过处理输入特征,对那些含有大量冗余特征的数据集比较有效;
通过处理类标签,适用于类数足够多的情况;
通过处理学习算法,在同一个训练数据集上多次执行不同算法可得到不同的模型。
下面分别对其中比较典型的方法,如Bagging、AdaBoost、基于不同学习算法的集成算法进行描述。
Bagging算法是一种根据均匀概率分布从数据集中重复抽样的技术[28],是一种较简单的集成学习方法。
AdaBoost算法是一种典型基于提升的集成学习方法,它将每一个分类器的预测值进行加权,而不是使用多数表决的方案。这种机制允许AdaBoost惩罚那些查准率很差的模型[28]。
在同一训练数据集上进行不同的算法得到不同的模型,然后再进行模型的投票,是一种常见的构建组合分类器的方法。不同学习算法的集成算法描述如图2所示。如前所述,本文拟采用该算法进行集成学习方式的自动标引。
2.3 用于关键词抽取的基分类器介绍
基于机器学习的自动标引的思想,就是将关键词的自动抽取看成一种分类问题。本节简要介绍已有的几个用于自动标引的基分类器,即条件随机场模型、支持向量机模型、多元线性回归模型、Logistic回归模型。此外,本文还给出两个常规的自动标引方法作为基准,以进行比较分析,分别记为基准模型1、2。
(1) CRF分类器
条件随机场(ConditionalRandom Fields,CRF)模型是一种概率图模型[31],标注序列的结构可以看作一般的无向图。CRF的优点是能有效整合多种特征,即使有些特征之间存在交叉现象,CRF还是能发挥很好的性能。Zhang和Wang等人曾利用CRF模型进行了关键词的自动抽取[19]。
(2) SVM分类器
支持向量机(SupportVector Machine,SVM)由Vapnik在1995年提出,用于解决二值分类模式识别问题[32]。2004年,曾华军等人在进行搜索结果聚类研究时,利用SVM进行显著短语的提取[33]。2006年,张阔提出基于SVM自动标引模型[14]。本实验中采用SVMlight[34]进行自动标引。、
算法:不同学习算法的集成算法
输入:训练集D={(x1,y1),…,(xm, ym)},其中xiÎX, yiÎY;测试集为T;每个基分类器Ci的查准率Pi;
输出:组合学习器C*(x)
步骤:
设定基分类器的个数k;
For i=1 to k {
由D创建训练集Di;
由Di构建基分类器Ci;}
For 每一条测试数据xÎT
C*(x) = Vote (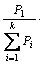 C1(x),
C1(x), 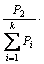 C2(x), …,
C2(x), …,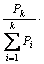
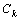 (x))
(x))
图2 不同学习算法的集成学习算法描述[28]
(3)多元线性回归分类器
线性回归是最简单的回归形式。曾华军等人利用多元线性回归模型(Multiple Linear Regression,MLR)进行显著短语的提取,他们通过实验发现在解决显著短语提取这一问题上,多元线性回归模型能取得较好的结果[33]。
(4) Logistic回归分类器
当因变量为二值类型时,Logistic回归(Logistic Regression,简写为Logit)更加适合样本标记的预测[35]。曾华军等人也利用Logistic回归模型进行显著短语的提取,并通过实验发现在解决显著短语提取这一问题上,Logistic回归模型能取得较好的结果[33]。
(5)基准分类器1
即基准模型1(BasaLine1,简写为BL1)中,利用归一化的词语的词频(TF)、归一化的逆文档频率(IDF)、词语长度作为考虑词语权重的因素,采用的权重计算公式如下:
Score =TF*IDF*Len(1)
(6)基准分类器2
即基准模型2(BaseLine2,简写为BL2)。与BL1不同的是,BL2除了考虑归一化的词语的词频(TF)、归一化的逆文档频率(IDF)、词语长度三个特征作为考虑词语权重的因素外,还另外加入了词语的首次出现位置(Dep)作为权重因素,权重计算公式如下:
Score =TF*IDF*Len*Dep(2)
利用以上模型对中文文档进行自动标引,要经过文本的自动分词、词性标注,特征计算,综合权重排序等一系列步骤。这些处理步骤以及这些模型的训练和测试的详细描述可参见文献36,由于篇幅限制,在此不再赘述。
2.4 基于集成学习的自动标引方法
本文以上述的BaseLine1、BaseLine2、MLR、Logit、SVM以及CRF等自动标引模型为基分类器,利用不同学习算法集成学习算法,进行基于集成学习的自动标引研究,本文将基于集成学习的自动标引方法记为Ens。
根据基分类器是否利用标引查准率进行加权,本文将基于集成学习的自动标引进一步分为基分类器不加权集成学习标引与基分类器加权集成学习标引。
(1)基分类器未加权集成学习标引
基分类器未加权集成学习标引方法就是指在基分类器进行投票表决时,各基分类器都是“平等”,即分类结果依据公式(3)得到多数表决的结果,作为最后的集成学习标引结果。
C*(x) = Vote (C1(x),C2(x),…,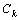 (x)) (3)
(x)) (3)
(2)基分类器加权集成学习标引
图2对基分类器加权集成学习方法进行描述。基分类器加权集成学习标引就是在基分类器进行投票表决时,各基分类器都是不“平等”,即分类结果采用公式(4)得到。
C*(x)= Vote (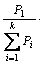 C1(x),
C1(x),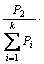 C2(x),…,
C2(x),…,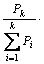
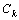 (x)) (4)
(x)) (4)
其中,k为基分类器的个数,每个基分类器Ci的查准率Pi经过归一化后变为:
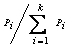 ,iÎ[1, k]。
,iÎ[1, k]。
3 实验结果分析
本节结合2.3小节中所描述的6种自动标引模型,对集成学习标引方法进行对照实验,并对实验结果进行分析。
3.1 实验数据与评价方法
(1)试验数据
本文以人大报刊复印资料[37]“人大2005年一季度经济类专题”库中经济类600篇论文作为数据集进行基于CRF的自动标引研究。数据集中的论文包括题名、摘要、关键词、带有段落和章节、图表标题信息以及参考文献等部分。
(2)评价方法
假设测试集中词语总数为n,自动标引系统标引结果如表1所示。将人工标引的结果分为两种情况,分别为人工标引为关键词的情况(即:(a+ c))与人工标引为非关键词的情况。人工标引为非关键词的情况,就是将人工标引关键词后,文本剩下的词作为非关键词。同理,自动标引结果也可以分为这两种情况,其中,(a + b)为标引系统标引的关键词总数。
表1 标引结果评价列联表
| 人工标引为关键词 | 人工标引为非关键词 |
标引系统标引为关键词 | a | b |
标引系统标引为非关键词 | c | d |
本文利用查准率(P)、召回率(R)以及F1值对模型标引性能进行评价,计算方法如下所示。
P=a/(a+b) (5)
R=a/(a+c) (6)
F1(P,R)=2PR/(P+R) (7)
本文利用查准率、召回率及F1值来进行自动标引模型的10折交叉验证[28]。
3.2 实验结果分析
利用3.1小节中的数据集进行集成学习标引方法的10折交叉验证,其中特征提取时利用的词典是通用与领域结合的分词词典。其中通用型词典是指直接将《人民日报分词词表》[38]做分词词典,领域词典是某一领域的常见关键词集合③。
根据3.1小节的测试数据和测评方法得到各基分类器的查准率如表2所示。
表2 基分类器自动标引结果的准确率
| BaseLine1 | BaseLine2 | MLR | Logit | SVM | CRF |
准确率 | 0.1188 | 0.171 | 0.2135 | 0.2116 | 0.5140 | 0.4702 |
归一化后的准确率 | 0.0699 | 0.1010 | 0.1256 | 0.1245 | 0.3024 | 0.2766 |
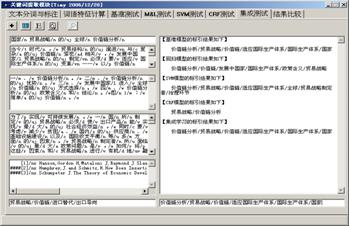
图3 基分类器不加权集成学习标引结果样例
图3为集成学习标引方法(基分类器未加权)标引得到的一条记录结果。附录为包含集成学习自动标引(基分类器加权)结果在内的测试集自动标引结果样例。
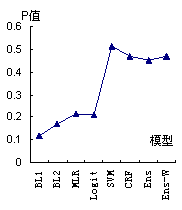
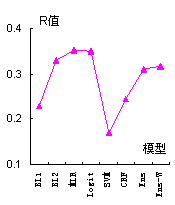
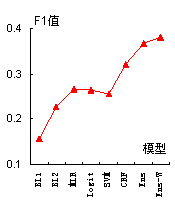
表3和图4给出了包括集成学习标引在内的8种标引方法的标引结果的P值、R值以及F1值。其中“Ens”表示分类器未加权的集成学习标引方法,“Ens-W”表示分类器加权的集成学习标引方法(Ensemble-WeightedBased Indexing),权重是采用表2中的经归一化的各基分类器标引准确率。
表3 八种标引方法的标引结果
模型 | P | R | F1 |
BL1 | 0.1188 | 0.2284 | 0.1563 |
BL2 | 0.1717 | 0.3302 | 0.2260 |
MLR | 0.2135 | 0.3519 | 0.2657 |
Logit | 0.2116 | 0.3488 | 0.2634 |
SVM | 0.5140 | 0.1698 | 0.2552 |
CRF | 0.4702 | 0.2438 | 0.3209 |
Ens | 0.4520 | 0.3097 | 0.3676 |
Ens-W | 0.4701 | 0.3178 | 0.3792 |
| 
| 
|
(a) P值比较 | (b) R值比较 | (c) F1值比较 |
图4 八种标引方法标引结果的P值(a)、R值(b)、F1值(c)比较图
由表3与图4可以看出,基于集成学习的自动标引方法在查准率和召回率上都在平均水平以上。F1值达最大值,因此综合考虑查准率和召回率后,基于集成学习的自动标引方法均要优于其他类型的标引模型,这表明基于集成学习的自动标引方法的有效性。
在基于集成学习的自动标引中,基分类器加权集成学习标引的结果,在查准率、召回率以及F1值上,均高于基分类器未加权集成学习标引的结果,这表明基分类器加权表决方法的有效性。本文今后将综合考虑其他指标,优化基分类器的加权方法,以提高基于集成学习方式的自动标引质量。
4 结论
本文利用不同学习算法集成学习算法,进行基于集成学习的自动标引研究。实验结果表明基于集成学习方法的自动标引,利用各种标引模型进行投票表决方式的自动标引,能提高标引结果的查准率和召回率。另外,在基于集成学习的自动标引中,基分类器加权集成学习标引的结果,均优于基分类器未加权集成学习标引的结果。
本文下一步的工作主要包括三个方面。其一,与其他基于集成学习的自动标引方法进行比较,即将Bagging或AdaBoost用于自动标引,与本文的方法比较,寻求一种相对高效的基于集成学习的自动标引方法;其二,下一步我们拟对CRF自动标引模型进行进一步优化,如将不同标引模型的结果作为CRF的输入,进行基于CRF集成的自动标引研究等;最后,对集成学习方式的加权投票方式进行进一步深入研究,寻找其他更合理的加权方法,如综合考虑查准率和召回率进行加权,进一步提高基于集成学习的自动标引方法的可靠程度。
注释
①本研究受“十一五”国家科技支撑计划重点项目(2006BAH03B02)、中国博士后科学基金资助项目(20080430463)、南京理工大学科研启动基金项目(AB41123)资助。
②数据集根据集成学习方式的不同,进行不同方式的处理,如本文实验中所采用的集成学习为:同一训练数据集上进行不同的算法得到不同的模型,从而进行集成学习方式的标引。因此此时的数据集1,数据集2,…,数据集n为同一训练数据集。
③通过对CSSCI(http://cssci.nju.edu.cn)数据库1998~2005年关键词数据的调查分析发现:关键词词库中多为4字词(这里所说的字是指单汉字,下同)和6字词。而通用分词词典中的词大部分为2字和3字词。由此可以看出,若利用通用词典进行分词,势必造成大量的关键词被“切碎”,从而无法识别和提取大量长度较长,并且比较专指的关键词。为了避免或者减缓这个情况的发生,本文采用的方法是将常见关键词加入到分词词典中,构建通用与领域结合的分词词典。
参考文献
1 曾元显. 关键词自动提取技术与相关词反馈. 中国图书馆学会会报,1997(59): 59-64
2 王强军, 李芸, 张普. 信息技术领域术语提取的初步研究. 术语标准化与信息技术,2003(1): 32-33, 37
3 Xun E., Huang C., Zhou M.. A Unified Statistical Modelfor the Identification of English BaseNP. InProceedings of 4th ACM Conference on Digital Libraries, 2000: 254-255
4 李素建, 王厚峰, 俞士汶等.关键词自动标引的最大熵模型应用研究.计算机学报, 2004,27(9):1192-1197
5 Cohen JD. Highlights: Language and Domain-independent Automatic Indexing Terms forAbstracting. Journal of the American Society for Information Science, 1995,46(3): 162-174
6 Luhn H P. A Statistical Approach to Mechanized Encoding and Searching ofLiterary Information . IBM Journal of Research andDevelopment, 1957, 1(4): 309-317
7 Salton G,Yang C S, Yu C T. A Theory of Term Importance in AutomaticText Analysis. Journal of the American society for Information Science,1975, 26(1): 33-44
8 马颖华, 王永成, 苏贵洋等. 一种基于字同现频率的汉语文本主题抽取方法. 计算机研究与发展,2004, 40(6): 874-878
9 Matsuo Y,Ishizuka M. Keyword Extraction from a Single Document Using Word Co-occurrenceStatistical Information. International Journal on Artificial IntelligenceTools, 2004, 13(1): 157-169
10 Chien L F. PAT-tree-based Keyword Extraction for Chinese Information Retrieval.In Proceedings of the 20th Annual International ACM SIGIR Conference onResearch and Development in Information Retrieval (SIGIR1997), 1997: 50-59
11 张庆国, 薛德军, 张振海等. 海量数据集上基于特征组合的关键词自动抽取. 情报学报, 2006,25(5):587-593
12 Ercan G., Cicekli I.. Using LexicalChains for Keyword Extraction. Information Processing and Management,2007, 43(6): 1705-1714
13 Hulth A. Improved Automatic Keyword Extraction Given More LinguisticKnowledge. In Proceedings of the 2003 Conference on Empirical Methods inNatural Language Processing, 2003: 216-223
14 Zhang K.,Xu H., Tang J., et al. Keyword Extraction UsingSupport Vector Machine. In Proceedings of the Seventh International Conferenceon Web-Age Information Management (WAIM2006) , 2006:85-96
15 索红光, 刘玉树, 曹淑英. 一种基于词汇链的关键词抽取方法. 中文信息学报, 2006,20(6): 25-30
16 Dennis SF.. The Design and Testing of a Fully Automatic Indexing-searching System forDocuments Consisting of Expository Text . In G. Schecter eds. Information Retrieval: a Critical Review. Washington D. C.: ThompsonBook Company, 1967: 67-94
17 SaltonG., Buckley C.. Automatic Text Structuring and Retrieval -Experiments inAutomatic Encyclopedia Searching . In Proceedings ofthe Fourteenth SIGIR Conference .New York: ACM, 1991: 21-30
18 Frank E.,Paynter G. W.. Witten I H.Domain-Specific Keyphrase Extraction. InProceedings of the 16th International Joint Conference on ArtificialIntelligence, 1999: 668-673
19 Zhang C.Z., Wang H. L., Liu Y., et al. Automatic Keyword Extraction from DocumentsUsing Conditional Random Fields. Journal of Computational Information Systems,2008, 4(3): 1169-1180
20 Turney P. D.. Learning to Extract Keyphrasesfrom Text. NRC Technical Report ERB-1057, 1999: 1-43
21 WittenI. H., Paynter G. W., Frank E., et al. KEA: Practical Automatic Keyphrase Extraction. In Proceedings of the 4th ACMConference on Digital Library (DL'99), 1999: 254-256
22 韩客松, 王永成. 中文全文标引的主题词标引和主题概念标引方法. 情报学报, 2001,20(2): 212-216
23 KeithHumphreys J. B.. Phraserate: An Html Keyphrase Extractor. Technical Report, University of California,2002: 1-16
24 侯汉清, 章成志, 郑红. Web概念挖掘中标引源加权方案初探.情报学报, 24(1):87-92
25 储荷婷. 索引自动化:自动标引的主要方法. 情报学报, 1993,12(3): 218-229
26 章成志. 自动标引研究的回顾与展望. 现代图书情报技术, 2007, (11):33-39
27 姜远. 集成学习及其应用的研究. 南京大学博士学位论文, 2004: 1
28 Tan P.,Steinbach M., Kumar V.. Introduction to Data Mining .Boston: Addison-Wesley,2006: 276-290
29 Schapire R. E., Singer Y.. BoosTexter: aBoosting-based System for Text Categorization. Machine Learning, 2000, 39(2-3):135-168
30 Weiss S.M., Apte C., Damerau F. J.,et al. Maximizing Text-mining Performance. IEEE Intelligent Systems, 1999,14(4): 63-69
31 LaffertyJ., McCallum A., Pereira F.. Conditional Random Fields: Probabilistic Modelsfor Segmenting and Labeling Sequence Data. In Proceedings of the 18thInternational Conference on Machine Learning (ICML01) ,2001: 282-289
32 Vapnik V.. The Nature of Statistical Learning Theory.New York:Springer-Verlag, 1995: 1-175
33 Zeng H. J., He Q., Chen Z., et al. Learning to Cluster Web SearchResults. In Proceedings of 27th Annual International Conference on Research andDevelopment in Information Retrieval (SIGIR'04) ,2004: 210-217
34 SVMlight(2005-12-20).http://svmlight.joachims.org
35 王济川, 郭志刚. Logistic回归模型――方法与应用. 北京:高等教育出版社, 2001
36 章成志. 主题聚类及其应用研究. 南京大学博士学位论文, 2007: 54-78
37 人大报刊复印资料(2007-12-01). http://art.zlzx.org
38 人民日报分词词典(2006-04-20).http://ccl.pku.edu.cn/doubtfire/Course/Chinese %20Information%20Processing/Source_Code/Chapter_8/Lexicon_full_2000.zip
章成志 男,1977年生,博士,南京理工大学信息管理系讲师,中国科技信息研究所在站博士后,主要研究方向为信息组织、信息检索、数据挖掘及自然语言处理。
附录: 测试集关键词自动提取结果样例
序号 | BaseLine1 | BaseLine2 | MLR | Logit | SVM | CRF | Ensemble |
1 | 非市场经济国家/反补贴法/集成电路产业/美国商务部/补贴/反补贴 | 航空工业/补贴/补贴政策/中国产业/产业补贴/国外 | 补贴/航空工业/补贴政策/产业补贴/产业/非市场经济国家 | 航空工业/补贴/补贴政策/产业补贴/产业/政策 | 产业补贴/补贴政策 | 航空工业/补贴政策 | 补贴/航空工业/补贴政策/产业补贴 |
2 | 国家产品贸易/产品贸易/关税与贸易总协定/透明度/国家产品/产品贸易企业 | 产品贸易/关税与贸易总协定/国家/透明度/贸易/产品 | 产品贸易/关税与贸易总协定/贸易/国家/产品/透明度 | 产品贸易/贸易/关税与贸易总协定/国家/产品/透明度 | 产品贸易/贸易 | 产品贸易 | 国家/贸易/产品/产品贸易 |
3 | 贸易投资一体化/贸易投资/发展中国家/发展中国家参与国际分工/要素分工/国际分工 | 贸易投资一体化/贸易投资/一体化/就业增长/江苏省/国际分工 | 贸易投资一体化/贸易投资/一体化/江苏省/实证分析/就业增长 | 贸易投资一体化/贸易投资/一体化/江苏省/实证分析/就业增长 | 贸易投资一体化/就业增长 | 贸易投资 | 贸易投资/一体化/贸易投资一体化/就业增长 |
4 | 价值链分析/价值链/贸易战略/价值链分析关注/适应国际生产体系/最终产品市场联系 | 贸易战略/价值链分析/价值链/全球价值链/国家/国际生产体系 | 价值链分析/价值链/贸易战略/全球/国家/适应国际生产体系 | 价值链分析/价值链/贸易战略/全球/国家/适应国际生产体系 | 价值链/贸易战略 | 价值链 | 价值链分析/贸易战略/价值链/国家 |
5 | 价值链分析/服务贸易/价值链分析关注/价值链/最终产品市场联系/贸易战略 | 服务贸易/服务贸易国际竞争力/服务/国际竞争力/竞争力/经济结构调整 | 服务贸易/竞争力/价值链分析/服务/因素/服务贸易竞争力 | 服务贸易/竞争力/因素/服务/服务贸易竞争力/服务业 | 服务贸易/国际竞争力 | 服务贸易 | 服务贸易/服务/竞争力/因素 |
6 | SPS协定/争端解决程序/检疫措施/SPS/协定/植物检疫措施协定 | SPS/SPS协定/协定/争端解决程序/牛肉/协议 | SPS/协定/SPS协定/争端解决程序/牛肉/美国牛肉 | SPS/协定/SPS协定/争端解决程序/牛肉/美国牛肉 | 欧盟和美国牛肉案 | 争端解决程序 | 争端解决程序/SPS/SPS协定/协定 |
7 | 保障措施/1974贸易法/贸易法/中国入世/1974/美国1974贸易法 | 保障措施/美国/立法/中国/保障措施立法/调查 | 保障措施/保障措施立法/立法/美国/中国/贸易法 | 保障措施/保障措施立法/立法/美国/中国/调查 | 特别保障措施 | 保障措施 | 保障措施/美国/立法/中国 |
8 | 1974贸易法/保障措施/贸易法/中国入世/1974/美国1974贸易法 | 多哈/反倾销/回合/立场/反倾销调查/外国反倾销调查 | 反倾销/多哈/国际合作/调查/1974贸易法/案件 | 反倾销/多哈/案件/调查/国际合作/WTO | 反倾销 | 反倾销/反倾销调查 | 反倾销/多哈/回合/立场 |
9 | 贸易转移效应/反倾销措施/贸易转移/进口来源地/反倾销保护/部分出口企业 | 反倾销保护/反倾销/反倾销措施/保护/经济效应/引发 | 贸易转移/反倾销措施/贸易转移效应/反倾销保护/反倾销/经济效应分析 | 反倾销保护/经济效应分析/反倾销/贸易转移/效应/经济效应 | 贸易转移效应/反倾销/经济效应 | 反倾销 | 反倾销保护/反倾销/经济效应/效应 |
10 | 公共利益/反倾销措施/国家利益/贸易救济措施/公共利益判断/国家整体 | 公共利益/反倾销/公共利益判断/利益/反倾销措施/判断 | 公共利益/公共利益判断/反倾销/利益/公共利益原则/判断 | 公共利益/公共利益判断/反倾销/利益/公共利益原则/判断 | 反倾销 | 反倾销 | 公共利益/公共利益判断/反倾销/利益 |