方志类古籍引书挖掘及其引书分析研究
衡中青1,2 侯汉清1
(1�南京农业大学信息学院 210095)
(2�佛山科学技术图书馆 广东佛山 528000)
摘 要 本文主要研究中国方志类古籍引书挖掘方法,并以旁征博引著称的广东方志类古籍《岭南丛述》(物产)为例,从引书的历史时期、高频被引书、作者生活地域和引书学科性质四个方面进行文献计量学研究,以期探讨中国方志类古籍的引书分析方法。
关键词 引书挖掘 模式识别 引书分析
1 引书识别方法的选择
引书,通常指古籍中引用的文献,古籍中引用文献的方式不同于现代汉语。古代文献的书写不分句读,大都没有标点符号,引用文献和他人话语时也没有注加引用符号,如《》和:“”;引书著录形式没有统一标准,有些引书用全名,有些用异名,有些用简称,随纂写人员行文习惯而异,没有统一引用标准,还有些干脆不用书名,只用作者姓名,如某某云,某某曰,等等。因此,古籍中的引用文字,与行文的其他文字没有区别,这给引书的识别带来极大的困难。人工阅读古籍时,若没有古代典籍的目录学、文献学和古代汉语等领域知识,是没有办法识别其中的引用文献的,即使具有这样的领域知识,工作效率也十分低下;而基于字符匹配的计算机,若不经过人为“训练”,则是一片茫然,无从识得引书。问题的解决办法是,由人来编制计算机软件,使计算机“具备”领域知识,辅助人来识别引书,编制引书索引,把人从繁重的引书识别和索引编制的工作中解放出来。
计算机引书识别是中文信息处理中自动分词的研究范畴,能否通过计算机自动分词的方法,把方志类古籍中的引书“分”出来?
目前,见诸报道的自动分词方法主要有三种类型:①机械分词法,又称词典式切分法;②语义分词法;③人工智能法,又称理解分词法。其中的词典式切分方法是当前应用广泛且十分有效的方法。词典法是目前常用的三大分词方案(词典法、基于规则切分标记法、人工智能法)之一,这种方法的关键技术和步骤有二:一是词典的构造;二是相应的匹配算法,有什么样的词典就有什么样的匹配算法,词典的构造是基础。词典构造的关键点在于词汇的完备性,无论匹配算法设计得多么精巧,词汇网罗不完全,文献的分词也是不完全、不准确的。本项引书识别研究若采用词典法,必要条件是构造一个词汇十分完备、历史上出现过的所有典籍书目词典,即古籍书目词典。但是,中国古代典籍无计其数、无法统计,且散佚太多,到现在为止,没有人能准确说出史上存佚的古籍数目和种类。现有的古籍目录,大多是典藏部门古籍目录,如书目文献出版社1990年代按学科门类出版过《北京图书馆普通古籍目录》15册。即使有通用性的古籍目录性著作,收书也不全面,如齐鲁书社1989年出版胡道静主编的《简明古籍辞典》收词才2000条,才及现存10万种的2%。因此,缺乏一种词汇完备的古籍书目词典,使得采用词典法寸步难行。因为,古籍中的引用文献五花八门,涉及各个学科,中国方志类古籍中的引书更是如此。方志被誉为“地方性百科全书”,引用的典籍也是百科全书式的。况且,有些引用的是地方文献,根本没有大规模地流通过,甚至引用后不久即散佚,少有人知,古籍词典无法收录这种书目。
综上所述,采用词典法自动识别中的引书理论上是可行的,但构建具有完备词汇的引书词典却十分困难。既然现有古籍目录不能提供完备的词汇,我们是否可以从方志类文献本身着手,来挖掘其中的引书?
2 模式提取
笔者在阅读方志类文献时,发现这样的语言学现象:①古人在引用文献时,为使句子语法完整、语义协调,通常在所引用的文献后面加上“云”、“曰”等谓语动词,我们称为引用方式规则,如“本草纲目云”、“五山志林曰”,等等;②古代典籍的起名也有一定规律,如:《丹铅余录》、《岭南异物录》等典籍名称的最后一字都是“录”字;再如:《南州记》、《粤东笔记》等典籍名称的最后一字都是“记”字,等等,我们称之为命名规则。这样,我们可以提取出这些引用规则和命名规则,应用这些规则(模式)来挖掘方志类古籍中的引书。
(1)引书引用语言模式
我们通过审读文献发现:纂写人员在引用某书时有某种语言习惯,如:“桂海虞衡志云”、“广东新语曰”等等引书引用语言模式。我们提取这些引书引用语言模式,或称引书规则,见表1。
(2)引书名称特征的语言模式
现代人编著学术著作,有其自身起名特点,如《植物学》、《动物学》、《中国科技史概论》,等等,书名后的“学”、“概论”等字表示该书的性质和特征。古人著书,亦是如此。我们通过审读文献发现,“志”、“记”、“疏”、“经”、“注”、“录”、“谱”、“纪”,等等文字使用频率较高,提取它们作为引书名称特征的语言模式,见表1。
(3)人名引用的语言模式
在中国方志类古籍中,常出现“某某云”、“某某曰”等字样,如“屈大均云”,“苏东坡曰”等等。通过审读文献,我们发现:在叙述某某云、某某曰时,其实质是在引用某某的著作。原因是,当代人不可能与古人直接对话,提及某个人名,实际上提及的是他的某种著作,再加上古代的通信远没现代这么发达,信息传播速度慢,即使是同时代在世的人,所提及的也是他的著作,上述“屈大均云”的本质是:屈大均的《广东新语》或其他著作云,而不是屈大均当面对方志纂修者说。其实,在现代学术研究中,提及某个人大都也是指的他的某种著作。
因此,我们把方志物产资料中提及的某某人,即引用的人名,也视作某人的著作,即引书。也就是说,把人名处理成引书。这种处理方法,难度较大,因为某些人可能撰著了不止一种著作,我们必须对这些著作加以区别,判断出某人说的话到底属于哪一种著作,这种判断是靠人工进行的。所提取的人名引用的语言模式亦见表1。
表1 引用语言模式表
引书引用语言模式 | 引书名称特征语言模式 | 人名引用语言模式 |
……云 | ……志 | ……云 |
……谓 | ……记 | ……谓 |
……曰 | ……纪 | ……曰 |
按…… | ……谱 | ……所引 |
参…… | ……注 | ……所云 |
按……云 | ……闻 | ……为 |
即……所谓 | ……考 | ……谓 |
即……所称 | ……说 | ……谓之 |
即……所载 | ……注 | ……言 |
…… | …… | …… |
表中“……”代表引书或人名。我们把这些模式分成前标志型(如:案……)、后标志型(如:……云)和封闭型(如:案……曰)三种类型。人名引用语言模式的3个模式与引书引用语言模式重复,可归并到引书引用语言模式库中。
3 引书识别过程
3.1 运用模式识别截取相关引书文字
上表列出的三种模式,可以帮助我们从外观上将可能是引书的部分抽取出来,至于是否真是引书,需人工进一步处理。引书识别就是应用这些模式来匹配文献,截取出可能是引书的部分文字,然后进行词频统计剔除、人工判别等,进一步准确地识别出引书,具体步骤如下:
①使用表1中的模式,到物产全文库中进行模式抽取。具体抽取的度(即前后截取字数),通过试验办法根据不同情况确定,对于前标志型或后标志型,取7-8个汉字,而对于封闭型,取两个标志符之间的内容。在识别算法上采用正则表达式进行。正则表达式是用某种模式去匹配一类字符串的一个公式。由一些普通字符和一些元字符组成。在此我们设计的正则表达式主要是进行字符串的搜索和提取的。
具体算法采用正则表达式。正则表达式就是用某种模式去匹配一类字符串的一个公式。由一些普通字符和一些元字符(metacharacters)组成。在此我们设计的正则表达式主要是进行字符串的搜索和提取的,例:ereg(“[\u4e00-\u9fa5]{8}曰$”, 源串,存贮变量)。
②对抽取结果进行过滤处理,用禁用符号替换掉无意义的字符如标点符号、数字等。依据词语轮排规律[1],采用左对齐及右对齐方式对抽取结果排序,以此进行模式修正。
左齐举例:
按肇庆志出高要山
按肇庆志凡深山皆有
按肇庆志凡深山皆有
……
右齐举例:
蛾成翼参南越笔记
拌食之参南越笔记
长雌音短南越笔记
……
③对所有抽取结果进行超长或超短的判别剔除工作。
例如:采用“按……云”模式抽取的“按此随时异名以米之红白壳之厚薄为高下农家有利其先熟者如夏至霜降八月白诸种皆应节而熟然夏至�入炊少饭故价廉于他种唯粳稻须上腴田种者颇少厥价较昴于他稻云”,显然不可能是引书,剔除。再如采用“……说”模式抽取的“…诸说”一例,也不可能是引书,剔除。
3.2 运用N�gram方法分词,提高引书识别准确率
作为引书识别方法,我们考虑能否结合模式识别,利用N�gram方法,进一步从前期模式识别结果中识别出引书,作为模式识别的补充。具体实现思路如下:
对前述模式抽取的结果看作一个整体,应用N�gram进行分词,设定2≤N≤8,对结果进行词频统计,并计算各N�gram字串的得分值。
需要说明的是,在此应用N�gram方法,不需要进行全切分,对于左对齐的情况,从左方开始进行N�gram切分,对应于右对齐的情况,只需要从右方开始进行N�gram切分,而对于左右都有标志语的,则取其中间文字,不需要应用N�gram。举例如下:
左齐的情况:按肇庆志出高要山(注:“按”字是行文模式标记符,不计)
切分结果:肇庆/肇庆志/肇庆志出/肇庆志出高/肇庆志出高要/肇庆志出高要山
右齐的情况:蛾成翼参南越笔记(注:“记”是引书特征模式标记,不可去掉)
切分结果:笔记/越笔记/南越笔记/参南越笔记/翼参南越笔记/成翼参南越笔记/蛾成翼参南越笔记
两端的情况:按阮志云(注:“按”、“云”为封闭标记符,不计)
切分结果:阮志
经过上述根据模式特征对N�gram方法的简化设计,可以大大减少识别噪音,提高识别准确度。根据以上两种方法的结合应用,抽取出得分超过阈值的N�gram字串,进行总排序,并适当去除低分词。对于识别结果,由于存在引书子串的同频问题,需要进行合并处理。如上述切分结果中,“肇庆”是“肇庆志”的子串,如其频率相同,则仅保留父串“肇庆志”。经过以上处理,再经人工判别,形成最终模式识别引书集合。引书识别的流程图如图1。 图1 引书识别流程图
图1 引书识别流程图
4 系统实现
引书识别的基础工作是《方志物产》全文数字化并存入数据库。为此,我们建立了相应的全文数据库系统。在开发工具的选用方面,考虑到前述方志类文献的行文特点,选用Borland Developer Studio 2006作为开发工具,具体采用其Delphi for the Microsoft.NET Framework模块作为开发环境,提供了多种对数据库操作的引擎,共享能够运行在.NET框架上的超过20种语言的组件与源代码,支持UNICODE编码规范,易于维护移植。数据库选用SQL Server,有较强的可伸缩性与可用性,具有企业级数据库功能,支持UNICODE。系统运行环境是可以支持.NET Framwork的任何操作系统。
计算机引书识别系统的主要功能有:引书模式库维护、引书模式识别等。
引书模式库维护:增加和删除模式。发现新的模式时可随时添加到库中;发现某个模式不合适时,也可随时删除。界面如图2。
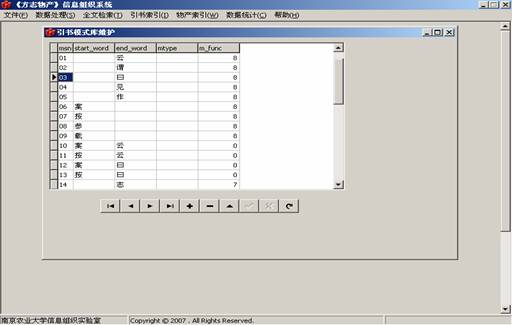
图2 引书模式维护界面图
引书模式识别:利用模式库中的模式扫描文档库,并按要求截取可能是引书的文字,生成模式识别结果集,然后经人工判别出引书,形成引书结果集。界面如图3。
5 引书分析
本部分主要以清代方志类古籍《岭南丛述》之物产部分门目为例,利用上述引书挖掘系统识别出的引书,从引书的历史时期、高频被引书、作者生活地域和引书学科性质四个方面进行文献计量学研究。
5.1 《岭南丛述》简介
《岭南丛述》[2-4],60卷,清人邓淳编,是一部岭南地区(广东、海南、广西部分、福建部分)百科全书式地方性记述文献。全书共分40目,其中涉及物产的有1134条,所引用文献的数量庞大,有着十分重要的文献学价值和科技史价值。
对《岭南丛述》(物产)中引书进行统计发现,作者邓淳共引用了2467次各类引书和其他文献。其中,诗词歌赋谚谣共引用171次。由于诗词歌赋谚谣极具分散性,一首诗常为多个作品所载,难于归结于某种引书。故笔者在进行引书统计时,没有计入诗词歌赋谚谣。按此原则,最终统计出351种引书,引用次数为2296次,平均每条物产引用两次之多。引书中官修方志有33种(明代2种,清代31种),约占9%;总引频次为405次(明代128次,清代277次)。其他各书为私人著述和官修典籍。这351种引书中有14种(引用405次)无法确定作者和年代。
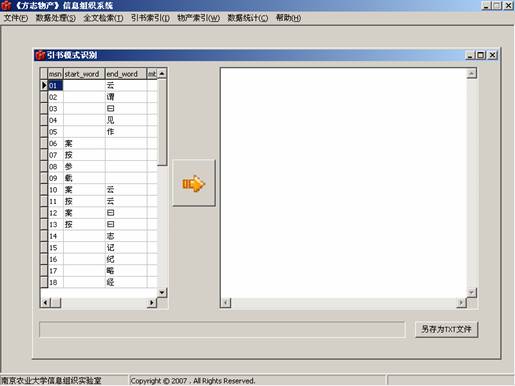
图3 引书模式识别界面
5.2 引书的成书年代分析
为了便于统计,笔者参考中国农业科技史历史分期[5],以及《岭南丛述》(物产)中的引书情况,将挖掘出的引书划分成先秦、秦汉等七个历史时期。因为《岭南丛述》成书于清道光年间,故清代指的是道光以前的清代。另外还有部分引书无法查知成书年代,无法归入上述七个历史时期,所以另外设立一“不明”项。历代引书种数、引书频次见表2。
为直观起见,笔者据表1画出各历史时期引书种数柱形图(图4)、总引频次柱表图(图5)。
从表2、图4和图5可以看出,引书种数最多的是宋元时期,有88种(其中宋代82种),最少的是先秦,只有17种,引书种数从高到低的排列次序为:宋元、清、三国两晋南北朝、明、隋唐五代、秦汉、先秦。总引频次最多的是清代,达756次,最少的是先秦,只有62次,总引频次从高到低排列次序为:清、宋元、三国两晋南北朝、明、隋唐五代、秦汉、先秦。
表2 《岭南丛述》(物产)历代引书
历史时期 | 引书种数 | 总引频次 | 平均引用次数 |
先秦 | 17 | 62 | 3.6 |
秦汉 | 21 | 102 | 4.9 |
三国两晋南北朝 | 56 | 366 | 6.5 |
隋唐五代 | 42 | 218 | 5.2 |
宋元 | 88 | 406 | 4.6 |
明 | 51 | 363 | 7.1 |
清 | 62 | 756 | 12.2 |
不明 | 14 | 23 | 1.6 |
合计 | 351 | 2296 | 6.5 |
作者引用最多的是宋代文献,这说明宋代科技文化发达,图书内容质量高,史料价值大,保存也比较完好。宋代引书最多,从一个侧面印证了历史上宋代是我国封建社会科技文化高度发达的历史时期。清代的总引频次高,是因为作者所引清代的文献内容与作者所撰述的内容相近,且年代近,文献散佚少。
全部引书高达2296次,清以前达1517次,说明作者邓淳博览群书、学识渊博,《岭南丛述》(物产)有着极高的学术水平与文化价值。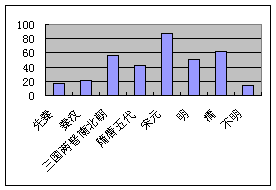 图4 《岭南丛述》(物产)引书(种数)的时代分布
图4 《岭南丛述》(物产)引书(种数)的时代分布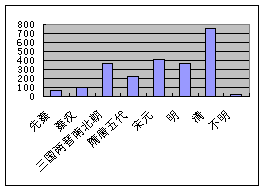 图5 《岭南丛述》(物产)引书(总引频次)的时代分布
图5 《岭南丛述》(物产)引书(总引频次)的时代分布
5.3 高频被引书分析
一种著述的被引用频次高,说明该书内容对撰述者来说参考价值大,资料性强。一位作者有多种著述被引用,且所占整个引书种数的比例高,说明这位作者与引用者研究兴趣相关性大。表3列出前10种高频被引书(简称高引书)。
表3表明,清代屈大均的《广东新语》被引频次最高,达207次,是邓淳撰著《岭南丛述》(物产)最有价值的参考资料。《广东新语》等10种高引书(仅占总引书的2.84%)的总被引频次高达903次,占《岭南丛述》(物产)总引频次(除诗词引用)的39.29%。由此可见,古代引书也符合《科学引文索引》创始人加费尔德提出的“文献集中定律”[6]。另外,需说明的是,表3同时又是被引频次最高的10位作者,兹不重复列表。
表3 《岭南丛述》(物产)前10种高引书
序号 | 引书名称 | 总引频次 | 作者 |
1 | 广东新语 | 207 | (清)屈大均 |
2 | 黄志 | 123 | (明)官修方志 |
3 | 岭外代答 | 117 | (宋)周去非 |
4 | 本草纲目 | 89 | (明)李时珍 |
5 | 岭表录异 | 73 | (唐)刘恂 |
6 | 岭南杂记 | 64 | (清)吴震方 |
7 | 粤东笔记 | 64 | (清)李调元 |
8 | 南方草木状 | 62 | (晋)嵇含 |
9 | 太平御览 | 57 | (宋)李� |
10 | 粤中见闻 | 47 | (清)范端昂 |
5.4 引书的地域分析
地域角度的引书分析,首先根据识别出的引书查找作者,再查证籍贯,最后归入到地域分类表中。凡无作者或作者籍里不详的引书一律标为“不明”。据此,共查得309种引书的作者籍贯,占整个引书种数的88%,这309种引书的总引频次为2139,占所有引书总频次的93%。分类表设立岭南地区、长江下游、黄河流域等六大地域,这些地域无论在人文还是自然方面都具有域内相似性和稳定性。详细统计情况见表4。
表4 《岭南丛述》(物产)引书作者的地域分布
作者地域 | 引书 种数 | 总引 频次 | 平均引 用频次 | 所 含 省 份 |
岭南地区 | 76 | 787 | 10.4 | 广东、广西、海南、福建 |
长江下游 | 102 | 580 | 5.7 | 浙江、上海、江苏、安徽 |
黄河流域 | 91 | 396 | 4.4 | 山东、河南、河北、山西、陕西、内蒙古、甘肃 |
两湖流域 | 26 | 225 | 8.7 | 江西、湖南、湖北 |
西南地区 | 14 | 151 | 10.9 | 四川、重庆、云南 |
东北地区 | 0 | 0 | 0 | 辽宁、吉林、黑龙江 |
合计 | 309 | 2139 | 6.9 | |
作者地域 | 引书 种数 | 总引 频次 | 平均引 用频次 | 所 含 省 份 |
岭南地区 | 76 | 787 | 10.4 | 广东、广西、海南、福建 |
长江下游 | 102 | 580 | 5.7 | 浙江、上海、江苏、安徽 |
黄河流域 | 91 | 396 | 4.4 | 山东、河南、河北、山西、陕西、内蒙古、甘肃 |
两湖流域 | 26 | 225 | 8.7 | 江西、湖南、湖北 |
西南地区 | 14 | 151 | 10.9 | 四川、重庆、云南 |
东北地区 | 0 | 0 | 0 | 辽宁、吉林、黑龙江 |
合计 | 309 | 2139 | 6.9 | |
从表4可以看出,长江下游作者的引书种数最多,达102种。究其原因是这个地域历史上发达的经济带动文化的大发展,撰著的典籍数量多且质量高,因而传播广泛、保存久远。黄河流域的引书种数居第二,一是因为这个地区范围广,从西北的甘肃到黄海之滨的山东,二是因为历史上山东、河南曾是中国科技文化的中心地带。但长江下游和黄河流域的平均引用频次低于平均数,是因为这两个地区的引书数量多,基数大。
东北地区没有引书,可能的原因:一是由于该地域开发较晚,经济、科技、文化欠发达,撰述数量少;二是由于路途遥远,传播范围小,岭南无法获取,难以利用;三是东北地区与岭南地区地域差异性大,其物产差异性也大,因而有关物产著述的内容亦难以参考利用。
岭南地区作者的总引频次最高,是因为《岭南丛述》(物产)引用的文献是为了记述岭南地区的物产,物产极具地域性,因而不得不大量征引地方文献(主要记述某一特定地域事物和事件的文献),这些地方文献主要是明清两代岭南官修方志(33种,405次),由于官府参与,保存完好、齐备,查找易得方便。但是,岭南地区作者的总引频次最高,并不能说明岭南地区历史上经济文化发达。一旦去除官修方志,岭南地区作者的引用情况立即发生了很大的变化(见图6),无论是引书种数(43种),还是总引频次(382次)都远低于长江下游(102种,580次),亦低于黄河流域(91种,396次)。这种情况也说明,记述某一地域事物和事件的地方文献,其参考资料很大程度上依赖于其地的官修方志。官修方志在《岭南丛述》(物产)的引用中占着举足轻重的地位。
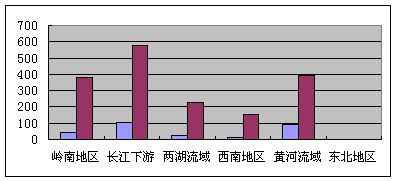
图6 《岭南丛述》(物产)引书作者的地域分布(官修方志除外)
5.5 引书的学科分析
《岭南丛述》(物产)引用了351种引书,涉及各个学科门类。笔者依据这些引书的内容与物产的关联程度,把它们分为官修方志、农书、杂记、诠释考证等10个类。诠释考证类包括字书、训诂、考证及为其他文献作注等解释性图书;杂记类包括四库史部、子部的杂史类、传类、杂家类、小说家类等具有多个主题且与物产关联程度不甚紧密的图书;其他类是指不能归入上述9类的图书,如:郑氏曰、种树者等不能归类或是无法查证内容的引书。表5是这10个类的引书种数、总引频次的统计数据。
据表5的数据可知,无论是引书种数还是总引频次,杂记类都高居榜首,约占一半。这个现象说明,杂记类文献是《岭南丛述》(物产)主要引书来源,而不是与物产紧密相关的物产博物类、农书类、医药著作类、官修方志类。可以想见,古人撰著方志类古籍的参考文献主要是与撰著内容不太紧密联系的文献。为了更为直观地说明《岭南丛述》(物产)的引书结构,按表5数据绘出各类引书总被引频次柱形图(图7)。
表5 《岭南丛述》(物产)引书分类统计表(按种数多少排列)
序号 | 类 别 | 引书种数 | 总引频次 | 平均引用频次 | 举 例 |
1 | 杂记类 | 163 | 1158 | 7.1 | 岭表录异、岭外代答、游宦纪闻等 |
2 | 官修方志类 | 33 | 405 | 12.3 | 黄志、广州府志、南海县志等 |
3 | 诠释考证类 | 27 | 112 | 4.1 | 尔雅注、正字通、山海经注、通雅等 |
4 | 农书类 | 26 | 131 | 5.0 | 荔枝谱、龙眼谱、南方草木状等 |
5 | 物产博物类 | 25 | 157 | 6.3 | 南州异物志、博物志、博物要览等 |
6 | 史地典籍类 | 25 | 49 | 2.0 | 史记、五代史、马总通历等 |
7 | 其他类 | 20 | 48 | 2.4 | 郑氏曰、梦香船、种树者等 |
8 | 药物著作类 | 18 | 217 | 12.0 | 本草纲目、本草拾遗、政和本草等 |
9 | 诗话类 | 9 | 12 | 1.3 | 竹坡诗话、渔洋诗话、柳亭诗话等 |
10 | 诗文集类 | 5 | 7 | 1.4 | 曲江集、�山集、东坡集等 |
| 合计 | 351 | 2296 | 6.5 | |
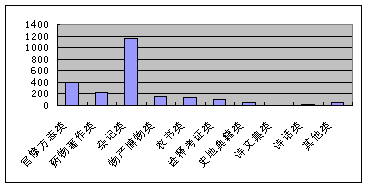
图7 《岭南丛述》(物产)引书的分类统计(总引用频次)
6 结语
本文应用模式识别与N�gram相结合的方法挖掘《方志物产》中的引书,提出了一种新的古籍引书挖掘方法,拓宽了古籍内容研究的思路。本文对挖掘出的引书从历史时期、作者地域、学科性质及高频被引书四个方面分析了《岭南丛述》(物产)的引书构成和来源组成情况,对引书分析进行了摸索。本文的目的并不仅仅在于方志类古籍的分析和得出的数据,而是在于分析方法的探索和分析结果对农史研究的思考:我们从哪些分析角度出发,才能从最大的广度和深度上探寻农业古籍的内容结构,为农业古籍的“辨章学术,考镜源流”提供量化研究方法,并为农史研究人员从资料来源和收集上拓展新的途径;同时,引书分析的结论能为农史研究提供哪些明证和启示。
参考文献
1 白振田.基于向量空间模型与规则匹配相结合的文本层次分类系统的研究.南京农业大学硕士论文,2006.6
2 杨宝霖.《岭南丛述》及其作者东莞人邓淳.东莞文史资料选辑第十三期,1988.9
3 陈伯陶.宣统《东莞县志》
4 袁应淦.民国《茶山乡志》
5 张芳,王思明等主编.中国农业科技史.北京:中国农业科技出版社,2001.9
6 加费尔德著;侯汉清等译.引文索引法的理论及应用.北京:北京图书馆出版社,2004.8
衡中青 男,佛山科学技术学院图书馆副研究馆员,博士。
侯汉清 男,南京农业大学教授,博导,中国索引学会副理事长。