基于词表和N-gram算法的新词识别实验
曹 艳 杜慧平 刘 竟 侯汉清
(南京农业大学信息管理系 210095)
摘 要 目前未登录词问题仍然很大程度上影响着自动标引和信息检索的效率。本文提出了一种选择期刊论文的题名和摘要作为训练语料,利用N-gram算法切分和停用词典等过滤筛选非专名的新词识别方法。该方法主要分为两步:先进行N元切分,保存关键词候选集并统计词频;然后进行一系列的过滤,主要有词频阈值限定、前停后停词典过滤、相邻词比较、子父串比较、抽词词典和过滤词典的过滤,最后进行人工判别。对实验结果的测评表明这一方法是简便易行的。训练语料可以不用全文,只用题名和摘要;在新词识别上,摘要可以代替题名。
关键词 N-gram算法 未登录词 新词识别 停用词典 过滤词典
1 引言
随着社会的飞速发展,大量新词语不断涌现。其中,有中文人名、地名、产品名、机构名、外国译名、时间词等专有名词,“一次性用品”等派生词,“八荣八耻”、“买单”、“秀”、“APEC”等简称、方言词语、行业用词、音译词、外来字母词、港台用词及其他与领域相关的术语,这些词语为未登录词或新词。
目前,大多数检索系统都是基于模式匹配的,这都需要多个词典作为匹配规则库,所以词典的规模和更新完善情况在很大程度上影响标引和检索的质量。汉语分词是中文信息处理的基础,在汉语分词方法里,简单的模式匹配算法、基于规则的方法和基于统计的方法,大部分都需要利用词典进行匹配,但这些词典覆盖率有限,而且对具体的应用领域变化的适应性较差,所以要及时补充新词、更新词典。另外,语法分析、主题词表的更新、自动标引和自动分类中分类知识库的完善都需要及时发现新词,这些仅靠人工识别无论在速度上、时间上还是在数量上都是远远不够的,因此需要计算机自动去发现新词。
国内现阶段对未登录词的研究主要集中在专有名词识别上,如利用隐马尔可夫模型(如HMM Tool)、角色定义、语料库训练等[1]方法识别中外人名和地名,一般都利用对语料库的学习,提出专用字的规律和统计数据进行未登录词的识别。但是在真实文本中,非专名的未登录词占了相当大的比例[2]。在非专名问题上,中科院计算所[3]利用大规模网页作为语料库进行重复串查找,在建立的背景词串集合基础上,通过评价函数、过滤规则库处理得到新词。刘建舟、何婷婷等[4]提出一种定期从网络上自动下载HTML页面组成动态语料库,采用统计的方法,并改进两个传统参数(互信息和log-likelihood ratio)进行新词识别。这些方法大部分是基于Web的,虽然能够及时发现数量比较多的新词,但也存在诸多不足之处,第一,web上内容的真实性本身就是一个值得讨论的问题,重复的网页比较多(为了提高排名,人为重复引用);第二,web页面内容(包括文本、图片等)用词没有经过规范,随意性非常大,这些严重影响着提取出的新词质量;三是都用到了传统的或改进的互信息和log-likelihood ratio两个参数或设定权值进行词加权处理,计算量比较大而且复杂;第四,要求大规模网页作为语料库,对全文文本进行切分工作量非常庞大,处理时间长,很难付诸实际应用。
本文主要从信息检索的角度,提出了一种选择期刊论文的题名和摘要作为训练语料,利用N-gram算法切分和停用词典等过滤筛选的非专名新词的识别方法。
2 N-gram算法识别新词的设计思路
2.1 训练文本的选择
本文使用的数据源是上海图书馆全国报刊索引数据库收录的2004-2006年期刊论文MARC记录,从中选择经济大类的1000条数据作为第一轮测试文本。主要是因为期刊品种多,内容丰富,发行快、流通面广,连续性也强[5],伴随着期刊的发行,必出现大量的新词;同时,期刊论文内容成熟可靠,格式也比较规范,通常作者会随文给出摘要、关键词、分类号、文献标识号等,所以被学术界视为权威性的知识来源,从中提取的新词具有可靠性和稳定性,经常被用于词典编纂、汉语分词、语法分析、自动标引和信息检索等方面。
本文没有选择期刊全文作为训练文本,主要是考虑到N元切分本身时间复杂度就很高,全文切分工作量太大,处理时间太长。而一篇完整的论文都随文提供题名、摘要。摘要是以提供文献内容梗概为目的,拥有与文献同等量的主要信息。张琪玉[6]认为,如果从针对文献整体的检准率的角度看,文献题名中的词最有效,依次为文献中的小标题和章节名、文献摘要、文献正文中的词;文献摘要对文献整体而言,检索效率大致与文献中的小标题和章节名相当。在标引源权值设计上,侯汉清[7]将标题、摘要、正文的权值分别设为5、3、1。因此,为了提高识别算法的速度和效率,本项研究选用期刊论文的摘要和题名部分作为训练文本。
2.2 测试内容及实验方法的特点
本实验有两项内容:一是测试本文算法在提取新词方面的功效如何;二是比较在提取新词数量与质量方面,摘要能否代替题名。
本文新词识别算法的特点在于:①分学科进行。在过滤算法中要选用对应学科的抽词词典,以减少人工判别的工作量;②动态的算法。本算法是一个不断积累、准确率越来越高的过程,每次将筛选掉的过滤词加入原有的过滤词典,参加下一轮n元切分后的算法过滤;③首次提出利用前停词典、后停词典筛选关键词候选集的方法,同时加入特例词典以减少因使用前停、后停词典带来的新词被过滤的概率;④计算简单、参数设置比较少,并且切分与过滤之间、各步过滤算法之间可合并,也可拆分,可灵活选用其中的某一个或多个过滤算法进行计算。另外,当对相同数据源的切分结果(关键词候选集及频次)选用不同过滤算法组合时不必再重复进行n-gram切分。
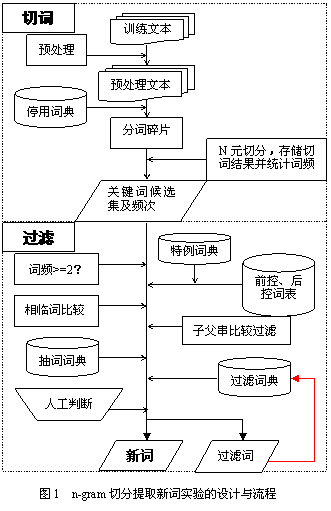
3 新词识别的步骤(见图1)
3.1 切词
(1)训练文本的选择见前文,不赘述。
(2)对训练文本作如下预处理:将数据源表中题名、文摘字段出现的诸如20010$a、□$a之类的标识符替换成空串;将空格、回车符及标点替换为“/”。
(3)将预处理文本与停用词典进行模式匹配,文本中含有停用词的地方全部替换成切分标志“/”。
(4)N元切分并统计词频。
利用停用词、空格、回车换行符、标点等作为分词标志把长的文句拆分为句子片断或子串,利用N-gram算法对拆分后的片段进行切分,记录候选关键词及词频。
本实验设置取词长度最长为12。如题名“构建黑龙江省与俄罗斯远东地区经贸合作H型产业模式”,由于“与”是停用词,所以此题名被划分为两个子串(子串1――“构建黑龙江省”,子串2――“俄罗斯远东地区经贸合作H型产业模式”),进行N元切分后,子串2的结果如下:
1元组:俄|罗|斯|远|东|地|区|经|贸|合|作|H|型|产|业|模|式
2元组:俄罗|罗斯|斯远|远东|东地|地区|区经|经贸|贸合|合作|H型|型产|产业|业模|模式
……
12元组:俄罗斯远东地区经贸合作H|罗斯远东地区经贸合作H型|斯远东地区经贸合作H型产|远东地区经贸合作H型产业|东地区经贸合作H型产业模|地区经贸合作H型产业模式
3.2 过滤
1000条记录训练文本的题名(T)、摘要(A)、题名+摘要(T+A)分别被切分出42535、208637、234276个候选关键词,各词频段的词条数及所占比率统计如下(表1):
表1 题名、摘要、题名+摘要的N元切分结果统计
| Freq N_gram | 1(次) | 2-10(次) | 11-99(次) | >=100(次) | 总 计 |
| num | 比率 | num | 比率 | num | 比率 | num | 比率 |
| T | 39061 | 91.833% | 3277 | 7.704% | 195 | 0.458% | 2 | 0.005% | 42535 |
| A | 183739 | 88.066% | 23238 | 11.138% | 1596 | 0.765% | 64 | 0.031% | 208637 |
| T+A | 200730 | 85.681% | 31468 | 13.432% | 1985 | 0.847% | 93 | 0.040% | 234276 |
表1表明,不论是摘要、题名,还是题名+摘要,切分出的候选关键词条中频次为1的数量非常大,占90%左右。在数据源够大的情况下,N元切分后的词条,词频越高则成词的可能性越大,而一些低频词往往是错切词,可直接排除,以减少后继各过滤算法的数据量,提高运行速度。本文设置词频阈值r为2,即排除掉词频为1的词条。
对剩下的10%左右的词条进行以下一系列过滤:
3.2.1 基于前停词典和后停词典的规则过滤
在现代汉语构词法中,“词根+词缀”构成的派生词是合成词构成的一种常见方式。词缀是只能粘附在词根上构成新词的语素,本身不能独立构成词,意义虚化且位置比较固定,只表示比较抽象的概括的意义。如“老师”、“刀子”中的“老”和“子”,意义非常虚,实际上已没有意思,成为汉语词语双音节化的一种手段。只能粘附在词根前面的词缀称为前缀,粘附在词根后面的词缀称为后缀。现代汉语中的前缀有“初第老”等,后缀有“子们头的着了过”等[8]。
利用现代汉语的此语法规则,本实验根据词缀的位置不同和一些无意义的符号(如“□”)收集整理了只能放在词首和词尾的字和符号,建立了前停词典、后停词典、特例词典。
前停词典:该词典中的字或符号一般出现在词尾,很少出现在词首。在分词后的词条中,若词条的词首为该词典中的字或符号,则该词条属于错切词,应过滤掉,除非成词,特例词典中含有这一词条。如“其”、“头”、“子”都是后缀,一般很少出现在词首,而“””是后引号,在词首也没意义,则n_gram表中出现的“头角”、“子公”、“”旅游”等词条在此算法中被过滤掉,而“子公司”成词,因特例词典中已收录该词,所以不被过滤。
后停词典与上相反,若某词条的词尾为该词典中的字或符号,则该词条属于错切词,应被过滤掉,除非特例词典中含有它。如“初”、“第”、“老”等,n_gram表中的“世纪初”、“为第”等词条在此步骤被过滤掉,而“府第”成词,因特例词典中已收录该词,所以不会被过滤掉。
3.2.2 相邻词比较筛选
词长(设词长为N)相等,并且连续的N-1个字或字符相同,也即只有第一个词条的首(尾)字或字符与第二个词条的尾(首)字或字符)不同,其余字或字符要全部相同,满足这两个条件的两词条互称为相邻词。如前文2元组中“经贸”和“贸合”,这两个词条就互为相邻词。对切分后n_gram表中的词条观察统计发现,词频相同的两个相邻词,大多都是语词被截断切开的词条,没有意义,而两者中若是有某一个词频高,则其成词的可能性高于另一个。因此设计了如下过滤算法:如果两个相邻词的词频相同,则两词均被过滤掉;若其中一个词条的词频高于另一个,则保留词频高的词条。如,在摘要的n_gram表中,“经贸”、“贸合”的词频分别为19、3,由于 “贸合”的词频低于“经贸”,因此“经贸”被保留,“贸合”被过滤掉。
3.2.3 子串、父串的比较[9]
子串是由父串中连续若干个字符组成的,表示在父串中的一个子集。子串、父串是相对来说的,如:“经贸合作”对“远东地区经贸合作”是子串,后者是其父串;但对“经贸”来说,“经贸合作”又变成了父串,“经贸”是其子串。
顾名思义,子父串比较就是将一个子(父)串与其父(子)串比较过滤。本算法中涉及两个参数,一是父串与子串词长间的相对值p(即父串长度与子串长度之差),第二个是父串与子串之间词频的相对值q(即子串词频与父串词频之差),这两个参数可随自己训练文本的长度与实验要求不同进行调整。
对于某一个词条I的所有父串来说,当词条I的词频与其父串词频之差大于q时,若父串与词串I的词长之差小于或等于p,则保留词条I,而将其父串过滤掉;若词串I的词频减去其父串词频的差不大于q时,则保留父串,过滤掉词串I。而对于词条I的所有子串来说,当其子串的词频减去词条I的词频之差小于或等于q时,则将其子串过滤掉,保留词条I;否则,要再进一步判断词条I与其子串的长度之差是否小于或等于p,若成立,则过滤掉词条I,并保留其对应的父串。
例如: n_gram表中有以下几个词条:虚拟价值链-5,价值链-21,价值-103。对“价值链”来说,其父串是“虚拟价值链”,子串有“价值”。不考虑前面的各步过滤算法,用此例来说明子父串比较算法。对“价值链”来说,它与其父串“虚拟价值链”的词频之差为16,大于设定的q,同时词长之差为2,小于等于设定的p,所以将其父串“虚拟价值链”过滤掉,而保留词条“价值链”;对于其子串“价值”来说,它们的词频之差等于82,大于q,同时,它们的词长之差为1,小于等于p也是成立的,所以此时将“价值链”过滤掉,而保留其子串“价值”。
3.2.4 用抽词词典进行过滤
抽词词典是比较规范化的、用于自动标引的主题词表。它按照学科设置,因本实验选取的是经济大类的1000条记录,过滤时要选用对应的经济大类抽词词典,外加通用的地名表。系统目标是发现新词,所以要排除掉词典中已经收录的语词。实验中用的经济类抽词词典的规模是14292个主题词,经抽词词典过滤后,题名还剩候选新词277个,摘要剩2073个。
3.2.5 用过滤词典筛选
过滤词典是每轮实验数据经切分过滤后,再由人工判别,将过滤算法中未筛掉的错位切分、数字等无意义的词串另作标记,后又将其提取出来加入原有的过滤词典,因此说本实验的过滤算法是一个不断积累、动态的过程。
3.2.6 人工判别新词
人工判别的时候,将新词、通用词、过滤词作不同的标记。本实验选取的1000条经济类记录,从摘要提取新词297个,从题名提取新词33个。
4 实验结果评测与分析
4.1 结果评测
在经过词频阈值限定、前停和后停筛选、相邻词比较、子父串比较、抽词词典过滤后,训练文本中题名、摘要、题名+摘要N元切分出的词条已分别过滤掉99.35%、99.01%、98.95%的噪声,所以本实验的过滤算法自动去除了99%左右的无用词条,极大地减少了人工判别的工作量。
同时,引入准确率P来衡量过滤效果,由于本文只是实验性的训练文本,初始过滤词典几乎为空,随着切分文本的不断更新、增多,过滤词不断增加,准确率P会越来越高。
准确率(P)=新词个数/候选新词个数
据此可计算题名的准确率P1=32/277=11.55%,摘要的准确率P2=297/2073=14.34%,题名+摘要的准确率P3=478/2450=19.51%。
4.2 结果分析
针对题名、摘要、题名+摘要识别出来的新词进行比较分析,结果发现有以下几个特点:
(1)比较前文计算出的P1 、P2 、P3可以看出,利用题名+摘要作为实验数据新词识别的效果最好,不仅能提取更多的新词,而且准确率更高。
(2)题名中提取的新词有很多是摘要中提取的新词的子串(如表2)。
表2 题名与摘要中新词的比较
| 题 名 | 摘 要 |
| 助学贷款制度 | 国家助学贷款制度 |
| 亚式期权定价 | 平均亚式期权定价 |
| 农村土地制度 | 农村土地制度改革 |
| 企业知识型员工 | 民营企业知识型员工 |
| 证券市场制度 | 中国证券市场制度变迁 |
(3)抽词词典的规模对新词识别的影响。本文分别利用小型经济类抽词词典(含14292个主题词)、大型经济类抽词词典(含149279个主题词)分别对题名切分进行了实验,结果如下:利用前者题名中能识别出新词32个,利用后者识别出6个非专名未登录词(中国-东盟自由贸易区、后配额时代、企业知识型员工、货币政策有效性、世界遗产地、亚式期权定价)。比较发现,前一种方法识别出的32个新词中有26个是大型抽词词典中已有或相类似的,所以相应学科抽词词典的规模影响着新词识别的数量。
(4)摘要中识别出的新词比题名中识别出的新词多,且摘要中识别出的新词包含了题名中的新词。在利用小型抽词词典时,摘要中识别出新词297,而题名只有32个,其中只有3个词(都市圈、后配额时代、工程量清单)是摘要中未提取出来的,其他29个是同于或类似于(见表2)摘要中识别出的新词;利用大型抽词词典时,摘要中提取非专名未登录词195,而题名只有6个,且全部出现在摘要新词识别集合中。所以从摘要中提取的新词比题名要多很多,只要对摘要进行切分过滤就可识别出大量的非专名未登录词。
5 结语
本实验试验了一种简单易行的、以期刊论文摘要作为语料识别非专名新词的方法。实验的结果表明算法是可行的。现在本实验中的算法已成功地应用于经济以外的其他学科,分别提取出不同数量的新词。
实验发现有些方面尚需改进。首先,测试文本数据量还需要扩大,以确定何种数量的训练文本实验效果最好。其次,抽词词典的规模、类别与运算速度、准确率之间的权衡。实验中用小型抽词词典时,题名、摘要中分别识别出非专名新词32个和297个,其中有很多是大型抽词词典中已列入的主题词,这就在一定程度上增添了手工判别的数量,同时影响了过滤算法的准确率;但是,在用大型抽词词典实验时,运行速度相对前者要慢得多,以后需进一步改进算法,提高运行速度和准确率。再次,切分及过滤算法中涉及到的几个参数都是可变的,它们的取值在一定程度上也影响了新词的识别,如N元切分过程中n、子父串比较中p和q、词频阈值r的取值,用户可以根据需要灵活设置参数的取值,但这要经过大量实验测试。同时,人工判别新词受到个人智慧、经验、知识体系等各方面的影响。最后,利用了停用词典过滤,可以减少后继切分的数据量。但前停、后停用词典的制作需要一个不断调整、不断积累的过程,可以说停用词典的规模和准确性很大程度影响着切分、过滤算法的有效性。
参考文献
1 苏菲,王丹力,戴国忠.基于标记的规则统计模型与未登录词识别算法.计算机工程与应用,2004(15):43-45
2 陈小荷.自动分词中未登录词问题的一揽子解决方案.语言文字应用,1999(3):103-109
3 邹刚.基于Internet的新词自动检测.[2006-6-10].http://www.software.ict.ac.cn/seminar/lectures/20040520-%BB%F9%D3%DAInternet%B5%C4%D0%C2%B4%CA%D3%EF%D7%D4%B6%AF%BC%EC%B2%E2.ppt
4 刘建舟,何婷婷,骆昌日.基于语料库和网络的新词自动识别.计算机应用,2004,24(7):132-134
5 赖茂生,徐克敏等编著.科技文献检索.北京:北京大学出版社,1994
6 张琪玉.自然语言检索中各种因素对检索效率的影响.张琪玉情报语言学论文集.北京:北京图书馆出版社,1999.5
7 侯汉清,薛鹏军.基于知识库的网页自动标引和自动分类系统的设计.大学图书馆学报,2004(1):50-55
8 朱宏一.汉语词缀的定义、范围、特点和识别――兼析《汉语水平等级标准与语法等级大纲》的词缀问题.语文研究,2004(4):32-37
9 张雪英.基于粗糙集理论的文本自动分类研究.南京理工大学[博士学位论文],2005.5
曹 艳 女,1983年生,南京农业大学信息管理系硕士研究生。
杜慧平 南京农业大学信息管理系硕士研究生。
刘 竟 南京农业大学信息管理系在读博士生。
侯汉清 南京农业大学信息管理系教授、博士生导师,中国索引学会副理事长。