古代农业专题资料自动编纂的设计和研究
常娥侯汉清
(南京农业大学信息管理系 210095)
摘 要 古代农业专题资料自动编纂是利用计算机自动从古代农业专题资料中发现并摘录与某一主题相关的农业资料,并编纂成册。本文首先阐述了古代农业专题资料自动编纂的意义,接着比较了它和自动文摘的关系,然后就其自动编纂的流程和算法进行了设计,最后总结本文的写作目的。。
关键词 古代农业专题资料 自动编纂 自动文摘 自动分词 篇章分割
1 古代农业专题资料自动编纂的意义
古代农业专题资料俗称古农书,是指古代论述农业生产及与农业生产有直接关系的知识著作[1],范围相当广泛,包括农、林、牧、副、鱼以及农产品加工等。简单地说,古代农业专题资料自动编纂是利用计算机自动从古代农业专题资料中发现并摘录某一主题的农业资料,并编纂成册。
南京农业大学中华农业文明研究院是国家级农史文献信息中心,收藏了大量的古代农业专题资料。以前本院手工编辑了很多农业遗产选集资料,手工编辑这些资料不仅投入了大量的人力、物力,而且编纂周期很长,所以研究古代农业专题资料自动编纂技术非常重要,主要表现在以下两个方面:首先可以提高本院农业遗产选集编纂的效率,其次由于到目前为止还未有人进行过这项研究,所以该研究填补了古代农业专题资料自动编纂方面的空白。本院的中国农业遗产研究室正承担着“中国农业科技遗产信息数据库”建设项目,不仅在中华农业文明网上成功地搭建了“中国农业遗产信息平台”,而且该数据库的建设工作已经取得阶段性的成绩,主要建成了以下几个数据库:农史论文题录库、古代农业专题资料目录库、农史论文全文库、专题文库、古代农业专题资料全文库、农业遗产选集图文库、农业典籍善本图文库和方志资料图文库,其中古代农业专题资料全文库收集了214种古代农业专题资料全文资料。作为本院的研究生,不仅要参加古代农业专题资料数据库的建设工作,而且要开展古代农业专题资料自动化、智能化处理的研究工作,古农书选集自动编纂就是研究任务之一。
2 古代农业专题资料自动编纂与自动文摘的关系
在研究古代农业专题资料自动编纂技术前,我们首先要弄清古代农业专题资料自动编纂与自动文摘的关系,否则这两个概念很容易混淆。文摘是指准确全面地反映某一文献中心内容的简洁连贯的短文,所谓自动文摘就是利用计算机自动地从原始文献中提取文摘[2]。古代农业专题资料自动编纂和自动文摘不是同一种技术,二者之间有区别也有联系。
首先,处理的对象不同。前者是针对古汉语语料展开的研究,后者主要是面向现代文本的技术。古汉语与现代汉语在词汇和语法上的区别如下:古汉语中,单音词占多数,现代汉语则以双音词为主;古汉语使用了丰富的文言虚词[3],如“之、乎、者、也”等,现代汉语放弃了所有的文言虚词,转而使用结构助词,如“的,啊,吗,呢”等;古汉语存在大量的词类活用、宾语前置、省略句等形式,这和现在汉语的语法有很大的区别,所以古汉语比现代汉语难理解。在这一点上,古农书选集自动编纂比自动文摘更具挑战性。
其次,处理的过程不同。前者主要是一种摘录的过程,而后者不仅是摘录,更重要的还是一种理解的过程。古代农业专题资料自动编纂是根据事先确定好的编纂主题,一般是先给出编纂关键词,然后自动到古代农业专题资料数据库中查找并摘录相应的内容,而自动文摘的中心内容是根据原文归纳提取出来的,所以就这个方面来看,自动文摘比古农书选集自动编纂的要求更高。
再次,处理的技术不同。古汉语与现代汉语存在很大的差别,目前已有的很多中文信息处理技术,由于是面向现代汉语的,所以不能直接应用到对古汉语的处理中。比如,就自动分词技术而言,已有的分词词典对于古汉语并不适用。
最后,二者的联系。无论是古农书选集自动编纂还是自动文摘,汉语词间没有空格,因而都存在着自动分词问题。由于二者都有自动摘录的过程,所以它们都需要通过识别句意的转换,来确定摘录的范围。虽然现有的中文信息处理技术不能直接应用到对古汉语的处理中,但是很多经验和算法是可以借鉴。自动文摘已走过了40年历史,积累了丰富的经验,为本研究奠定了一定的基础。
3 古代农业专题资料自动编纂的流程设计
古代农业专题资料自动编纂的首要条件是将古农书资料电子化,我院通过购买《中国基本古籍》光盘数据库和扫描识别本院保存的农业典籍,目前已经积累了214种古代农业专题资料的数字化资料,为本研究的展开提供了基础。古代农业专题资料自动编纂的过程主要包含以下几个步骤:首先,确定编纂的主题,即给出编纂关键词;其次,在数据库中查找古代农业专题资料;再次,摘录与该主题有关的古农书信息;最后,整理排版,编纂成册。整个过程主要由计算机自动完成,具体流程设计如图1所示:

图1 古代农业专题资料自动编纂流程图
(1)给出用于描述编纂主题的关键词。如“麦”。
(2)根据关键词查找并记录编纂主题所在文档的名称。如,检索出“麦”在《齐民要术》、《王祯农书》等古代农业专题资料的文档中有描述。
(3)提取关键词所在文档的章节或者段落。如果关键词出现在某个章节中,首先需要分割这个章节,然后再提取与本主题有关的内容,提取的可能是整个章节,也可能是其中的某些段落。如《齐民要术》第二卷的“大小麦第十”,这一章内容都是有关“麦”的,应该全部提取出来,又如《齐民要术》第二卷的“小豆第七”中提到“小豆大率用麦底然恐小晚……”,这只有一段相关,应该就提取这一段类容。
(4)将提取的内容按照“编号,书名,作者,朝代,注释,篇名,篇内正文”的格式整理排版。如图2所示:
图2 古代农业专题资料自动编纂排版图
4 古代农业专题资料自动编纂的算法设计
由上文可知,古代农业专题资料自动编纂分为四个步骤,其中涉及了信息检索、自动分词、篇章分割和句意主题转换识别等技术。本研究的核心步骤是第三步,即提取编纂主题所在古农书文档的章节或者段落。在中文信息处理技术中,篇章分割的主要任务在于通过对文档结构进行分析,寻找和查询有关的段落,并把找到的段落而不是整篇文档返回给用户[4],因此篇章分割技术可用于确定摘录的范围,是本研究的关键技术。
通常,文章并非仅仅是一系列句子的并排,而是组织完善、有中心思想的文字铺陈,提供读者阅览、欣赏、获得信息,或者与作者沟通等的功能[5]。在正常情况下,由一组句子构成一个主题单位,称为主题段落,一篇文档又由几个主题段落构成。但是,很多文档并没有明显的段落标记,所以必须找到一种方法将文章分段,每一段都涉及相同的主题内容。许多学者专家提出各种不同的看法,尝试建构主题段落里句子的关系以及主题段落彼此间的关系来进行文档分割。例如,Youmans提出了新词引入法[6],即记录文章某跨度内作者引入新词汇的数目,然后根据这样的统计数据,决定主题段落的边界。Morris 与Hirst提出词汇链的方法[7],企图找出词汇上的关连,然后使用这些关连性找出文章的结构。Hearst则提出了TextTiling算法[8],这是一种比较新颖的算法。TextTiling使用词频与逆向文件频率,先将文章切成一片片马赛克(Tile),然后通过计算文本块(block)之间的分界值,确定句意主题转换的边界。这三种算法都存在着一定的局限:新词引入法仅仅考虑词汇重复出现的因素;词汇链的方法仅仅找出词汇间有没有相近关系,然而却不规范关系的强弱;TextTiling算法只考虑名词,忽略其余类型的词汇,同时也忽略词汇共现的关系。
本院的电子化古代农业专题资料都是文言文,笔者拟将一本古农书当作一篇文档来处理,这样一篇文档往往涉及了很多主题,所以古农书选集自动编纂就需要清理这些文档的结构,按照编纂的主题分割文档,定位摘录与编纂主题有关的内容。针对这一要求,本研究借鉴TextTiling算法设计出古代农业专题资料自动编纂的算法,其中TextTiling算法主要是用来确定摘录的范围,其基本思想是在一篇文档中寻找从一个主题转到另一个主题的“过渡”部分。古代农业专题资料自动编纂算法的具体步骤如图3所示。 图3 自动编纂步骤图
图3 自动编纂步骤图
下文将对其主要步骤:分割章节、提取子句关键词、计算紧凑度、计算深度值和确定分割点,分别进行说明。
(1)分割章节。
剔除标点符号,将章节划分成固定长度的子句,子句之间的点称为间隔点。假设子句的长度为w,如何适当选定w是本算法重要的考量因素。w不能太小,因为这样包含的主题信息太少;也不能太大,这样对于主题边界的判定会比较不准确。
(2)提取子句关键词。
首先用停用词典过滤子句,然后采用最大匹配算法进行自动分词,处理所得的词语即视为子句的关键词。停用词典主要由文言虚词构成,分词词典主要由古代人名、地名、官名、书名、作物名、节气等专有名词构成。
(3)计算紧凑度。
紧凑度是指编纂主题在各个子句间隔点上的连续性。紧凑度低意味着前后的连续性差,可以作为分割的候选点。计算紧凑度的方法有新词引入法、词汇链法、文本块比较法、向量空间计分法等。本研究采用文本块比较法,即使用包含m个子句的移动窗,由第一个子句逐步往后移动,一次一个句子,计算移动窗内由子句构成的文本块的相关系数。文本块用向量表示,通常将每个单词在该文本块中出现的频次作为该向量的值。两个向量的规一化内积就是文本块的相关系数,即子句间隔点的得分。如果两个文本块中包含相同的单词越多,子句间隔点的得分越高。
假设存在文本块b1和b2,每个文本块都包含k个关键词,b1={keywordi-k,…,keywordi},b2={keywordi+1, …,keywordi+k+1},那么子句间隔点的紧凑度为:

其中,t表示两个文本块中所包含关键词的总个数,wt,b表示该词的权值,通常用该词在文本块中的出现的频次表示。由于得分值已经进行了规一化处理,所以score(i)介于0和1之间。本研究选择m=2,即每两个子句构成一个文本块,子句间隔点紧凑度的具体算法如下:
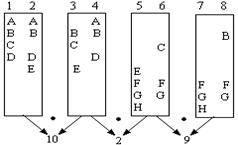
图4 文本块内积示意图
如图4所示,有8个子句,每两个子句组成一个文本块。即子句1和2是第1个文本块(b1),子句3和4是第2个文本块(b2),依此类推。计算b1和b2的相关系数,就得到子句2和3的间隔点的紧凑度,同样可以得到子句4和5、子句6和7的间隔点的紧凑度。
首先,计算每两个文本块向量的内积。
b1和b2内积:2*1(for A)+2*2(for B)+1*1(for C)+2*1(for D)+1*1(for E)=10
b2和b3内积:1*0(for A)+2*0(for B)+1*1(for C)+1*0(for D)+1*1(for E)+0*2(for F)+0*2(for G)+0*1(for H)=2
b3和b4内积:0*1(for B)+1*0(for C)+1*0(for E)+2*2(for F)+2*2(for G)+1*1(for H)=9
其次,进行规一化处理,得到子句间隔点的紧凑度。
子句2和3:score(1)=10/10.58=0.945
子句4和5:score(2)=2/8.77=0.228
子句6和7:score(3)=9/10.49=0.858
按照同样的方法,进行第二轮处理,即将子句2和3、子句4和5、子句6和7,分别作为一个文本块,计算得到子句3和4、子句5和6的间隔点的得分。
子句3和4:score(4)=6/8.77=0.684
子句5和6:score(5)=4/7.94=0.504
(4)计算深度值。
将某个间隔点的紧凑度和周围间隔点的紧凑度进行比较,相对值越低,那么该点的深度值就越大。具体计算方法是,将当前间隔点和左右相邻的间隔点紧凑度的高度差相加,作为深度值。例如,已知间隔点g1,g2,g3的紧凑度分别为s1,s2,s3,那么g2点的深度值为:(s1-s2)+(s3-s2)。并不是每个间隔点都有深度值,只有当某点的紧凑度低于左右相邻点的紧凑度时,才计算该点的深度值。所谓的紧凑度概念是相对的,在某些文本中,其内容的主题可能变化很大,例如文档的引言部分,覆盖了文档的全部内容。而与此相对应的是,一篇文章可能一连几页的主题变化都很细微,这时就需要选择那些虽然紧凑度值比较高,但是和周围点相比值又偏低的点,即采用深度计算。表1给出了各子句间隔点的紧凑度及其对应的深度值。
表1 深度值计算表
ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
紧凑度 | 0.47 | 0.21 | 0.07 | 0.09 | 0.27 | 0.16 | 0.13 | 0.23 | 0.12 | 0.28 | 0.23 | 0.2 | 0.27 |
深度值 | | | 0.60 | | | | 0.24 | | 0.27 | | | 0.15 | |
(5)确定分割点。
计算深度值的均值μ和标准方差σ,选择所有深度值高于μ-c*σ(c为常数,通常取0.5或1.0)的间隔点作为边界。由表1的数据可以得出,μ=0.315,σ=0.183,取c=0.5,阈值μ-c*σ=0.22,由于0.60>0.22,0.24>0.22, 0.27>0.22,所以紧凑度为0.07、0.13和0.12的子句间隔点可以选作分割边界。
在实际处理文本的过程中,本算法需要进一步调整和细化,以取得最佳编纂效果。例如,计算紧凑度和深度值的参数(子句词次序列的大小、文本块的大小等)得根据正在处理的文档进行调整。
5 结语
我国对于古籍数字化的研究才刚刚起步,很多工作都没来得及开展。有的学者指出数字化的古籍资源除了实现文本字符的数字化,具有基于超链接的浏览阅读环境和强大的检索功能外,还需具有研究支持功能[9]。也有学者提出希望建立古籍整理的专家系统,以实现古籍版本的自动校勘、自动编纂、自动断句标点、自动注释、自动翻译为白话等等[10]。到目前为止还未有人进行过古农书自动编纂的研究,加上古汉语自身的特点,所以这项工作存在一定的难度。笔者在这方面做了初步的尝试,目前古代农业专题资料自动编纂的实验系统已基本完成,并整理了《齐民要术》标点版全文资料作为该系统的实验数据,经过初步测试发现:当子句和文本的大小分别取15和2时,提取主题的符合程度较高。下一步的工作包括:在已有的古代农业专题资料数据库中进行大规模的测试,检验本算法的调适性;改进和完善古代农业专题资料自动编纂的实验系统。希望这项工作对他人的研究有些微的贡献,同时也起到抛砖引玉的作用。
* 基金项目: 科技部国家科技基础性工作专项资金项目(2002DEB30090)。
参考文献
1 王永厚. 中国古代农业专题资料及其珍藏.农业图书情报学刊(增刊),1995
2 刘挺,王开铸. 自动文摘的四种主要方法.At URL:http://hzq.chinalibs.net/book/l0248.pdf, 2005(8)
3 杨伯峻,何乐土. 古汉语语法及其发展.北京:语文出版社,1992.8
4 Christopher and HinrichSchutze著;苑春法等译. 统计自然语言处理基础.北京:电子工业出版社,2005.1
5 陈光华,陈信希. 文件内容之分析�语料库为本的模型. At URL :www.lis.ntu.edu.tw/~khchen/writtings/pdf/ ,2005(8)
6 G. Youmans・A New Tool for Discourse Analysis: The Vocabulary-Management Profile・Language,1991
7 J. Morris and G. Hirst・Lexical Cohesion Computed by Thesaural Relations as an Indicator of the Structure ofTexts・ComputationalLinguistics,1991
8 M. Hearst・TextTiling: AQuantitative Approach to Discourse Segmentation・University of California at Berkeley,1993
9 李国新. 中国古籍资源数字化的进展与任务. 大学图书馆学报,2002(1)
10 潘德利. 中国古籍数字化进程和展望. 图书情报工作,2002(7)
常娥 1979年生,南京农业大学信息管理系博士研究生。
侯汉清 南京农业大学信息管理系教授、博士生导师,中国索引学会副理事长。