中国电信黄页搜索引擎的设计思路
胡运发 陶晓鹏 王政华 杨笑天
(复旦大学信息科学与工程学院 上海200433)
摘 要 本文介绍了复旦大学所开发的中国电信黄页搜索引擎的研究背景,探讨了黄页搜索引擎系统面对的需求和相关设计方案,以及系统实现需要采用的软件、硬件、网路配置。黄页信息检索系统既是一种分类的搜索系统,又是同企业挂钩的商业搜索系统,代表了搜索引擎研究的前沿技术。
关键词 信息检索 全文检索 搜索引擎 黄页搜索 总体设计
1 研究背景
信息检索(Information Retrieval)这个术语是Calvin Mooers于1948年在MIT的硕士论文中首次提出的。它是指从文档集合中返回满足用户需求的相关信息的过程。作为一门学科,是研究信息的获取(acquisition)、表示(representation)、存储(storage)、组织(organization)和访问(access)的一门学问。在计算机科学发展的初期,因为信息有限、数据不多,对信息检索的需求不大,这门学科也没有受到足够的重视。到20世纪末,人类在数据、信息、知识等方面成果的迅速积累,世界到了一个“信息爆炸”的时代。同时,随着计算机科学突飞猛进的发展,人们越来越倾向于将各类信息以磁介质的方式存储。根据美国加利福尼亚大学伯克利分校研究人员发现,仅仅从1999年到2002年三年间,全球新生产出的信息量就翻了一番。2002年中,全球由纸张、胶片以及磁、光存储介质所记录的信息生产总量达到5万亿兆字节,约等于1999年全球信息产量的两倍,三年间的平均增速为30%。而新产生的信息中,大约有92%记录在硬盘等磁存储介质中。
信息爆炸带来了人类知识的极大丰富,只需要有计算机,有网络,你就可以获取一个巨大的知识宝库。但信息爆炸也同时带来了所谓的“混沌信息空间”(Information Chaotic Space)和“数据过剩”(Data Glut)等问题。一方面是信息的极大丰富,另一方面确实在浩如烟海的信息库中难以找到符合自己需求的内容。造成这种后果一方面是因为保存信息的数据量极其庞大,另一方面,也是因为信息的表达方式(数据存储方式)越来越多样化。
简单说来,数据可以分为结构化数据和非结构化数据两大类。所谓的结构化数据,就是那些可以存储在数据库里,用二维表结构来逻辑表达实现的数据,比如银行报表、职工信息表、企业财务报表等;反之,则可以称为非结构化数据,如文章、图片、MP3音乐等等。对于前者,当前的数据库管理系统(DBMS)已经能够满足绝大多数的需求。以Oracle、Microsoft为代表的各大公司所生产的数据库管理系统,能够将企业财务报表、职工信息表等结构化数据信息以二维表的方式整理存储,很好地满足企业搜索、修改、删除、添加等需求。然而,对后者的处理,则一直没有能够找到非常有效的方式,DBMS对于非结构化数据的先天不足,使得前者的技术很难应用于后者,而当前的检索则需要同时能够对结构化数据和非结构化数据展开,也就是我们所说的全文检索。
所谓全文检索,从广义上说,是以从文本一直到声音、图片、映像等数据为其处理对象,按照数据资料内容而非其大小、格式等外在表象为依据的一种检索系统。理想的全文检索系统应该能够以合理的方式组织各种数据,以优化的方式加以储存,然后以最快速、准确、全面、友好的方式将数据提供给用户。通过这种方式,用户可以在最大限度内使用自己所拥有的数据。在MIT、贝尔等实验室中,最先进的全文检索系统已经能够凭借一张照片而找出所有相关的文字、图片、影像等内容。
然而,就目前的计算机科学而言,这种高端的服务尚难以提供给普通用户,我们谈论最多的是狭义的全文检索系统,也就是基于文本的全文检索系统(Full-text Retrieval)。这种系统一般能够通过扫描文章中每一个字、词、句的方式来建立关于文章的索引,并保存关于字(或词)在文章中的位置,并在用户查询时,根据事先建立的索引进行查找,并最终将查询结果返回给用户。
在信息剧增、表现形式日益多样化的今天,对普通用户而言,传统的结构化数据获取、表示、存储、组织和访问方式已经远远不能够满足社会的需求,对全文检索(无论广义或者狭义)的研究也越来越受到重视。而搜索引擎正是研究成果的表现方式,作为一项当今社会获取信息最方便、有效、快速的手段,搜索引擎在社会生活的各个方面正发挥着越来越重要的作用。
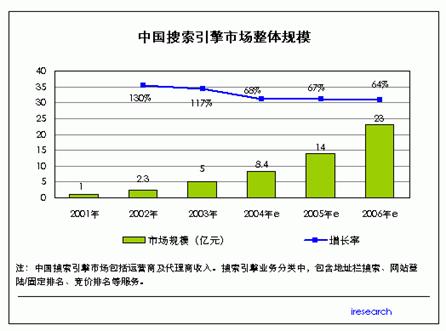
所谓的搜索引擎(search engines),是指对互联网上的信息资源进行搜集整理,然后供用户查询的系统,包括信息搜集、信息整理和用户查询三部分。它在很大程度上满足了在网页量大规模增加的现状下,从中方便获取信息这一关键需要。从中国搜索引擎市场的增长图(图1)中不难看出,这一技术背后巨大的商业价值。
图 1
2004年8月19日,全球最大的搜索引擎公司Google在纳斯达克成功上市,发行价为85美元。当日挂牌交易后股价立刻高开以95美元开盘,收于100.34美元,较每股85美元的发行价上涨18%,一天之内的成交量令人瞠目结舌地达到了2210万股,甚至超过1960万股的发行总量。次年,堪称中国Google的Baidu公司在纳斯达克上市,发行价27美元,一日之内股价上涨到84美元,涨幅311%,是纳斯达克史上涨幅最高的IPO。这一切清楚地表明了搜索引擎在当今全球经济中的分量。
然而,搜索引擎备受青睐的现状并不意味着非结构化数据获取这一问题已经得到了圆满解决。事实上,包括Google、Baidu、Yahoo在内的搜索引擎都在不同程度上存在各种问题,其中最为明显的一条,就是这些引擎全部都是通用搜索引擎,这意味着对于这些搜索引擎而言,无论数据来源是中国科学院还是街头小报,只要你的相关度越高,就能够越容易被用户所找到。同时,当所搜索的内容偏向于专业性质时,搜索的结果就明显不如人意了。以Google为例,搜索时下最为流行的“超级女声”,结果达1,750,000条,前10页共300条记录的相关性非常高,达到99%,但如果搜索“多播骨干网”,则结果虽然显示有292,000条,但真正相关不到30%。而对于搜索含义具有模糊性的内容则更是如此,如搜索“温泉关”,得出来30%是一部关于温泉关战役的电影,70%是关于温泉关战役的历史介绍,如果用户是希望进行一次希腊的旅游,显然不会很满意,而如果你同时输入“温泉关”和“旅游”关键字,则结果99%是关于“温泉”。可见通用的搜索引擎虽然颇为普及,但是在准确率、适用性方面仍然有不小的提升空间。
在这种情况下,对于搜索引擎的进一步研究,不仅仅具有较好的科研价值,而且还具有不小的经济价值。包括Microsoft、Baidu、Yahoo、Google、TRS在内的公司纷纷投入巨资,研究下一代搜索引擎。他们研究的方向多种多样,包括:
(1)希望了解用户搜索意图的智能搜索系统;
(2)将全文检索和早期的分类检索结合的网页库内容分类系统,比如,用户搜索“申花”,系统很可能不是将申花足球和申花电器放在一起,而是分门别类地展示;潜在相关性搜索,比如搜索“西红柿”,同时给出“番茄”的信息;
(3)结构化信息抽取系统,从非结构化的网页中,自动找到结构化的数据;
(4)自然语言处理、简单的语义语法分析系统;
(5)识别重复的系统;
(6)行业、类别优化的搜索系统,对某行业、类别进行预先划分的搜索系统;
(7)用户个性化数据采集系统;
(8)企业级搜索引擎系统,针对某企业内部数据的搜索系统;
(9)网页变化跟踪系统等等。
在这些令人眼花缭乱的发展方向中,研究最为深入、当前普及最广的,一是令页面搜索细化的“专业搜索”系统;二是企业级搜索引擎系统。
长久以来,搜索引擎的发展一直是努力“满足最大规模群体的需求,让尽可能多的人以尽可能通用的方式使用本系统”。而“专业搜索”的设计目的则大有不同,它希望能够通过对搜索范围的细化、分类,从而让搜索结果更为精确,更满足用户的需求。
从2005年开始,Baidu、Google等公司纷纷推出了自己的专业搜索网站。从最开始的图片搜索,到细化的新闻搜索、音乐搜索,一直到新出现的“博客搜索”,搜索引擎不断的朝细化、精确化的方向发展(见表1)。
表 1
| 细化的搜索范围 | 开展服务的公司 |
| 新闻搜索 | Baidu、Google、Yahoo、搜狗、中搜 |
| 音乐搜索 | Baidu、中搜、搜狗 |
| 博客搜索 | Oao |
| 图片搜索 | Baidu、Google、Yahoo、中搜、搜狗 |
| 学术文章搜索 | Google |
| 论坛搜索 | 奇虎、中搜、搜狗 |
| 图书搜索 | Google |
以Baidu为例,搜索关键字“关之琳 图片”,结果显示737,000项,然而第一页中匹配搜索的仅占30%,前10页匹配仅占25%,但如果用Baidu的图片搜索,则结果显示35,200项,99%符合搜索结果。可见虽然只是进行了简单的分类,但是对搜索结果产生了极为有利的影响。
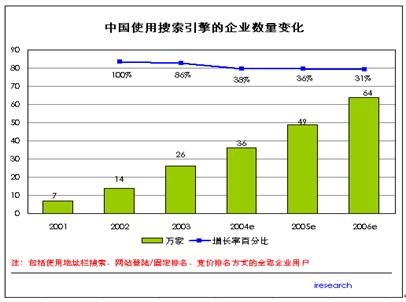
而企业级搜索引擎系统同样在2006年搜索引擎市场大放异彩,行业规模不断扩大,研究投入和参与的竞争者也不断增加。从图 2中可以看到,仅中国市场,2007年预计客户就达到1亿,而全球市场2007年则预计可能达到10亿美元。可见,企业对搜索引擎技术重视程度持续增加、投入资金持续增大。在当前知识经济的大潮下,一个企业如果要成长,信息畅通是不可或缺的条件,而信息检索系统则无疑是一个实际而有效的选择。
很多大公司已经投入到该类型课题的研究中,如:Autonomy、TRS、Yahoo、Microsoft、Google、Baidu、中搜,都已经致力于该课题的研究,并且都有了自己的产品。
在这种情况下,黄页信息检索系统作为搜索引擎研究的一个分支,既是一种分类的搜索系统,又是同企业挂钩的商业搜索系统。可谓得天独厚,站在了搜索引擎研究的前沿。
图 2
2 总体设计
2.1 需求约定
引进复旦大学上海(国际)数据库研究中心、上海旦茂数字技术有限公司已有的“互关联后继树全文检索引擎”产品,并进行客户化定制黄页搜索引擎,满足中国电信黄页全国企业信息的检索要求。
通过复旦大学项目组与中国电信黄页公司技术/业务人员合作开发的黄页搜索引擎项目,实现了黄页信息库与搜索引擎技术的有机结合,利用包括分词技术、高效索引、快速检索等在内的先进搜索引擎技术,实现黄页海量信息在高并发环境下的快速查询,融入黄页分类主题词等知识体系,完成一个能够适应黄页作为中国电信主要的信息提供商所需的先进的、具有一定的独有特点的黄页搜索引擎,作为黄页开展各项信息服务业务的应用平台。
(1)全文检索服务器的基本功能
①支持对分词数据库进行增、删、改操作;
②查询关键字的关联性,包括根据输入关键词的上下位词、同义词查询,或者自定义关联词,与黄页的分类主题词体系有机结合;
③支持大数据量的全文检索,按目前黄页的信息量,我们要求搜索服务器支持1000万条的数据量(每条记录大致1000个汉字左右);
④支持搜索结果按照一定要求进行排序;
⑤更新索引时不影响正常提供服务;
⑥支持JAVA、XML等技术开发接口,有利于系统的二次开发;
⑦全文检索服务器应具备可伸缩性,即当数据或查询量增加后能通过增加服务器达到扩充其功能的要求。
(2)与黄页信息系统的网关接口
①实现搜索引擎全文检索服务器与黄页信息系统数据的同步功能;
②同步功能包括两种模式:一种是批量模式(整库模式),即所有或部分数据重建索引,要求1000万条数据重建索引时间<10小时;一种是实时模式,即通过一个高效的接口,实现信息系统的变动数据与全文检索服务器的索引的同步。
(3)与应用系统的网关接口
全文检索服务器应提供方便的接口(如JAVA,XML等)技术使得应用系统应能调用全文检索服务器的相应查询服务,通过向全文检索服务器发送一定格式的查询条件获得结构化的查询结果(结果集合应能分页)。
(4)实现一个应用系统
①能够使用前述的各种技术和功能实现一个应用系统,该系统为一个WEB应用系统,实现通过关键词在户名、地址、电话和企业经营范围进行查询,并可以限定或不限定其地理位置(省、市);
②根据黄页公司现有词库,进行分词,并优化现有词库,达到企业检索的准确度;
③在查询结果中能反映关键词的相关词、上、下位词关系。根据黄页公司提供的词表实现检索引导。
(5)可以保证搜索服务器的长期稳定运行
服务器正常提供服务时间≥99.5%。
(6)查询结果返回时间
1000万数据中按一定语法进行关键字查询返回结果时间<1秒。
(7)在对大量数据进行查询时,服务器资源占用率没明显提高
(8)支持50个用户以上的并发查询
2.2 系统结构
总体结构如图3所示。
![]()
图3 黄页信息检索系统总体框架图
系统结构如图4所示。
![]()
图4 黄页信息检索系统结构图
2.3 系统组成和运行环境
(1)操作员终端
操作员终端主要完成本软件系统的各种功能操作。
①硬件:Intel P4 /AMD AthlonXP 2600+ 以上CPU (512MB内存、40GB硬盘 );
②OS:Windows XP/2003;
③软件:远程桌面链接。
(2)数据库服务器
即数据的存储设备。
①硬件:至强双处理器服务器 (512MB内存、40GB硬盘 );
②操作系统:Windows XP/2003;
③软件:Microsoft .NetFramework. 1.1以上,SQL Server 2000,互关联后继树检索引擎,互关联后继树全文数据库管理系统。
(3)网络系统
局域网网络采用10/100M交换式快速以太网,用以实现信息的实时传输。
3 基本设计概念和处理流程
3.1 系统基本设计
根据业务流程和用户需求分析的结果,目前主要向用户提供黄页信息索引创建,黄页信息添加/修改,黄页信息检索,与应用系统的网关接口四部分功能:
(1)黄页信息索引创建:主要对黄页关系数据库中相关信息进行全文索引,以此提高黄页信息检索的查准率、查全率和时间效率。
(2)黄页信息添加/修改:实现搜索引擎全文检索服务器与黄页信息系统数据的同步功能,同步功能包括批量模式(整库模式)和实时模式两种。
(3)黄页信息检索:主要实现对于用户的任意输入检索到相关性最高的公司名称。该查询类别分为准确查询和全面查询两种:准确查询力求找出最匹配用户输入关键字的公司条目;全文查询则罗列出与查询串相关的尽可能多的公司条目。
(4)与应用系统的网关接口:主要是提供相关的网关接口供二次开发使用。
3.2 系统基本流程
(1)黄页信息导入与创建全文索引
使用互关联后继树全文数据库管理系统对已有的黄页信息关系数据库中的相应信息创建全文索引留待后用。
(2)黄页信息检索
用户登陆到黄页信息检索服务器,通过互关联后继树检索引擎进行相关信息的检索。
(3)黄页信息的修改/添加
在服务器闲阶段(夜晚)使用互关联后继树数据库管理系统进行批量模式的修改/添加。服务器忙阶段使用互关联后继树数据库管理系统进行实时模式的修改/添加。
(4)二次开发
使用互关联后继树协同接口进行相关的二次开发。
3.3 软件分布结构
(1)操作员终端;
①服务器端控制软件;
②远程桌面链接;
③IE 6.0或以上;
④10GB以上的空余磁盘空间。
(2)数据库服务器
①Microsoft .Net Framework;
②Microsoft Internet InformationService 5.0或以上;
③IE 6.0或以上;
④SQL Server 2000或以上版本20GB以上空余磁盘空间。
基于上述的设计思路,复旦大学上海(国际)数据库研究中心、上海旦茂数字技术有限公司以及中国电信合作开发了“复旦大学黄页信息检索系统(简称黄页系统)”,为公司信息检索这一特定行业设计了符合该行业特点的搜索引擎。该项目历时一年,经过各方面的努力,获得了很大的成果。从理论上而言,本项目成功将互关联后继树模型运用到了实践中,将其从实验室搬进了办公室,从而获得了一个难得的、检验研究成果的机会;从实践而言,该项目获得了中国电信公司的极大好评,成功进入了第二期的研究和设计,而系统在市场的推广中,也获得了终端用户较高的评价。从对本项目的分析中,我们可以从中得到软件工程、自然语言处理、搜索引擎算法等方面的宝贵经验。本文通过对该系统的描述和分析,希望在给同黄页系统相关的、或者具有共性的行业进行搜索引擎的设计时,能够从文中获取一些启迪;并在对其他的特定场合下进行搜索引擎设计提供有益的思路。
胡运发 男,1940年生,复旦大学信息科学与工程学院教授,博士生导师,主要研究方向是程序设计语言、知识工程与知识库、专家系统与机器学习。
陶晓鹏 男,1970年生,复旦大学信息科学与工程学院副教授,主要研究方向是自然语言处理、文本管理、信息检索。
王政华 男,1980年生,复旦大学信息科学与工程学院硕士生,主要研究方向是全文检索、文本管理、信息检索。
杨笑天 男,1980年生,复旦大学信息科学与工程学院硕士生,主要研究方向是全文检索、文本管理、信息检索。